Overview
This page lists my publications in reverse chronological order, grouped by type:
- Books and book chapters
- Journal papers
- Conference papers
- Non-peer reviewed conference contributions
- Preprints
- Theses
You can also download a .bib file with all my publications.
Data releases and slides from my talks are listed on the main page.
Books and book chapters
-
Gustav Eje Henter, Simon King, Thomas Merritt, and Gilles Degottex (2016)
Analysing shortcomings of statistical parametric speech synthesis
Draft book chapter for Natural Speech Technology: Statistical and Machine Learning Approaches to Speech Recognition and Synthesis, edited by S. Renals, M. J. F. Gales, T. Hain, P. C. Woodland, S. King, and S. Cunningham
First posted online July 2018 (34 pages)
[ preprint | arXiv | abstract | .bib ]
-
Arne Leijon and Gustav Eje Henter
Pattern Recognition: Fundamental Theory and Exercise Problems
Course book for the M.Sc. course EQ2341 Pattern Recognition and Machine Learning at the School of Electrical Engineering and Computer Science, KTH Royal Institute of Technology, Stockholm, Sweden
Last revised in 2015 (283 pages)
[ book webpage | course syllabus | course web | .bib ]
Journal papers (peer reviewed)
-
Guillermo Valle-Pérez, Gustav Eje Henter, Jonas Beskow, Andre Holzapfel, Pierre-Yves Oudeyer, and Simon Alexanderson (2021)
Transflower: Probabilistic autoregressive dance generation with multimodal attention
Accepted for publication in ACM Transactions on Graphics (vol. 40, no. 6, pp. 1:1–1:13)
To be presented at SIGGRAPH Asia 2021
[ postprint | arXiv | abstract | .bib | project page | code | Colab | video examples | interactive demo | intro video ]
-
Patrik Jonell,* Birger Moëll,* Krister Håkansson,* Gustav Eje Henter, Taras Kucherenko, Olga Mikheeva, Göran Hagman, Jasper Holleman, Miia Kivipelto, Hedvig Kjellström, Joakim Gustafson, and Jonas Beskow (2021)
Multimodal capture of patient behaviour for improved detection of early dementia: Clinical feasibility and preliminary results
Frontiers in Computer Science (vol. 3, article 642633, pp. 1–22)
[ postprint | publisher (open access, with supplement) | abstract | .bib | project page ]
-
Taras Kucherenko, Dai Hasegawa, Naoshi Kaneko, Gustav Eje Henter, and Hedvig Kjellström (2021)
Moving fast and slow: Analysis of representations and post-processing in speech-driven automatic gesture generation
International Journal of Human-Computer Interaction (vol. 37, no. 14, pp. 1300–1316)
[ postprint | publisher (open access) | arXiv | abstract | .bib | project page | code (for Japanese) | code (for English) ]
-
Gustav Eje Henter,* Simon Alexanderson,* and Jonas Beskow (2020)
MoGlow: Probabilistic and controllable motion synthesis using normalising flows
ACM Transactions on Graphics (vol. 39, no. 6, pp. 236:1–236:14)
Presented at SIGGRAPH Asia 2020
[ postprint | publisher (open access, with supplement) | arXiv | abstract | .bib | code | intro video | video presentation ]
-
Simon Alexanderson, Gustav Eje Henter, Taras Kucherenko, and Jonas Beskow (2020)
Style‐controllable speech‐driven gesture synthesis using normalising flows
Computer Graphics Forum (vol. 39, no. 2, pp. 487–496)
Honourable Mention at EUROGRAPHICS 2020 (best paper award nominee, top 4 of 141 submissions)
[ postprint | publisher (open access, with supplement) | abstract | erratum | .bib | code | intro video | video presentation ]
-
Jaime Lorenzo-Trueba, Gustav Eje Henter, Shinji Takaki, Junichi Yamagishi, Yosuke Morino, and Yuta Ochiai (2018)
Investigating different representations for modeling and controlling multiple emotions in DNN-based speech synthesis
Speech Communication (vol. 99, pp. 135–143)
[ postprint | publisher | abstract | .bib ]
-
Gustav Eje Henter and W. Bastiaan Kleijn (2016)
Minimum entropy rate simplification of stochastic processes
IEEE Transactions on Pattern Analysis and Machine Intelligence (vol. 38, no. 12, pp. 2487–2500)
[ postprint | publisher | appendices | abstract | .bib ]
-
Arne Leijon, Gustav Eje Henter, and Martin Dahlquist (2016)
Bayesian analysis of phoneme confusion matrices
IEEE/ACM Transactions on Audio, Speech, and Language Processing (vol. 24, no. 3, pp. 469–482)
[ postprint | publisher | abstract | .bib ]
-
Petko N. Petkov, Gustav Eje Henter, and W. Bastiaan Kleijn (2013)
Maximizing phoneme recognition accuracy for enhanced speech intelligibility in noise
IEEE/ACM Transactions on Audio, Speech, and Language Processing (vol. 21, no. 5, pp. 1035–1045)
[ postprint | publisher | abstract | .bib ]
-
Gustav Eje Henter and W. Bastiaan Kleijn (2013)
Picking up the pieces: Causal states in noisy data, and how to recover them
Pattern Recognition Letters (vol. 34, no. 5, pp. 587–594)
[ postprint | publisher | supplement | abstract | .bib ]
Conference papers (peer reviewed)
-
Gustavo Teodoro Döhler Beck, Ulme Wennberg, Gustav Eje Henter, and Zofia Malisz (2021)
Wavebender GAN: Controllable speech synthesis for speech sciences
Extended abstract accepted for publication at the 1st International Conference on Tone and Intonation (TAI) 2021
[ preprint | abstract | .bib ]
-
Siyang Wang, Simon Alexanderson, Joakim Gustafson, Jonas Beskow, Gustav Eje Henter, and Éva Székely (2021)
Integrated speech and gesture synthesis
Proc. ICMI 2021 (pp. 117–185)
[ postprint | publisher (open access) | arXiv | abstract | .bib | project page | code | slides (w/o video) ]
-
Patrik Jonell, Youngwoo Yoon, Pieter Wolfert, Taras Kucherenko, and Gustav Eje Henter (2021)
HEMVIP: Human evaluation of multiple videos in parallel
Short paper in Proc. ICMI 2021 (pp. 707–711)
[ postprint | publisher (open access) | arXiv | abstract | .bib | code | test materials | poster ]
-
Moein Sorkhei, Gustav Eje Henter, and Hedvig Kjellström (2021)
Full-Glow: Fully conditional Glow for more realistic image generation
Proc. GCPR 2021
[ postprint | arXiv | supplement | abstract | .bib | code | slides | video presentation ]
-
Taras Kucherenko, Rajmund Nagy, Patrik Jonell, Michael Neff, Hedvig Kjellström, and Gustav Eje Henter (2021)
Speech2Properties2Gestures: Gesture-property prediction as a tool for generating representational gestures from speech
Extended abstract in Proc. IVA 2021 (pp. 145–147)
Extended Abstract Honourable Mention (given to the top 2 of 8 accepted extended abstracts, among approximately twice as many submissions)
[ postprint | publisher | arXiv | abstract | .bib | project page | poster | slides | extended study ]
-
Ulme Wennberg and Gustav Eje Henter (2021)
The case for translation-invariant self-attention in transformer-based language models
Short paper in Proc. ACL-IJCNLP 2021 (pp. 130–140)
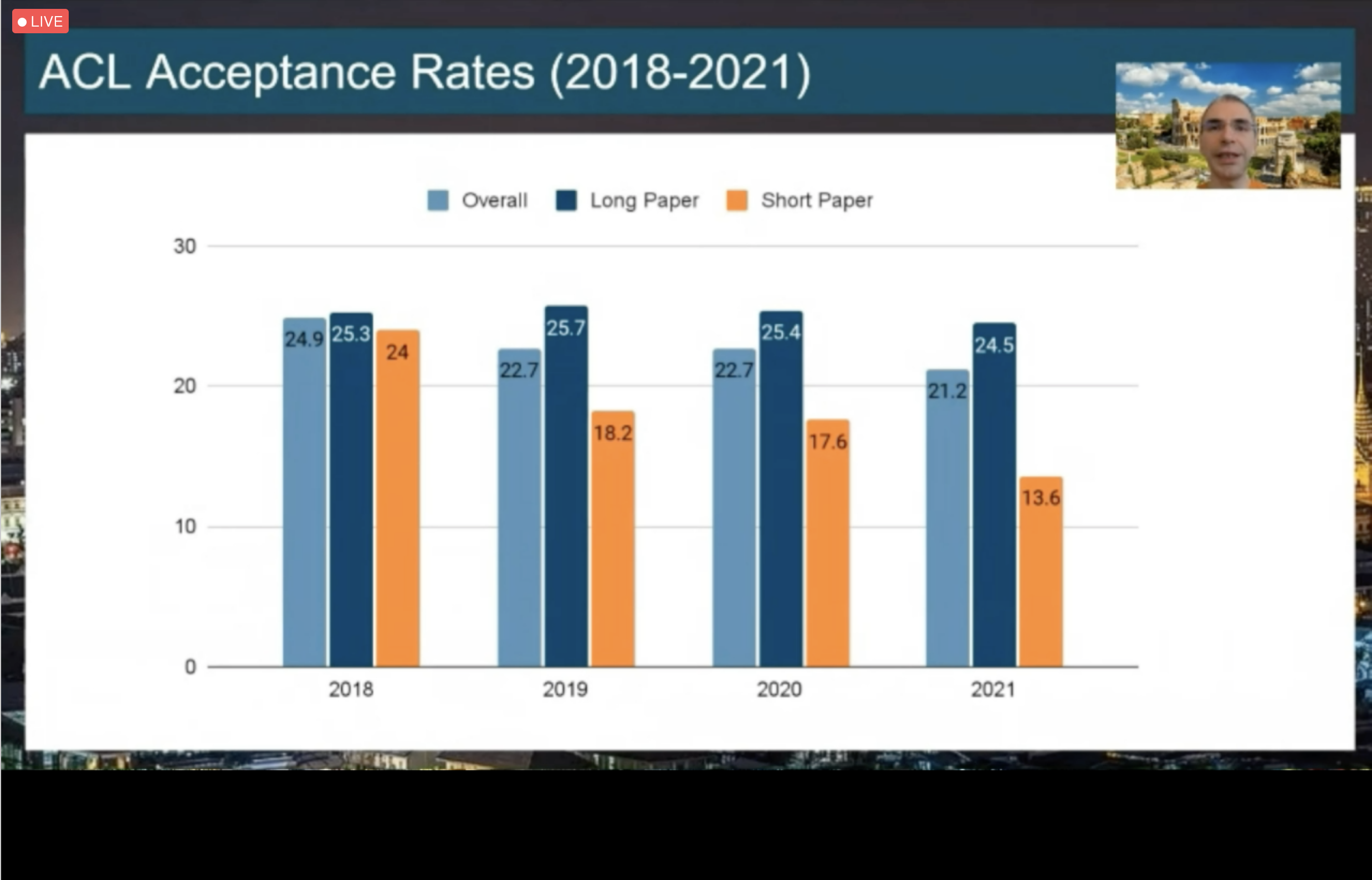
13.6% acceptance rate for short papers
[ postprint | publisher (open access) | arXiv | abstract | .bib | code | slides ]
-
Taras Kucherenko,* Patrik Jonell,* Youngwoo Yoon,* Pieter Wolfert, and Gustav Eje Henter (2021)
A large, crowdsourced evaluation of gesture generation systems on common data: The GENEA Challenge 2020
Proc. IUI 2021 (pp. 11–21)
[ postprint | publisher (open access, with supplement) | arXiv | abstract | .bib | project page | data releases | slides (w/o video) | video presentation ]
-
Taras Kucherenko, Patrik Jonell, Sanne van Waveren, Gustav Eje Henter, Simon Alexanderson, Iolanda Leite, and Hedvig Kjellström (2020)
Gesticulator: A framework for semantically-aware speech-driven gesture generation
Proc. ICMI 2021 (pp. 242–250)
Best Paper Award (given to 2 of 159 long paper submissions)
[ postprint | publisher | arXiv | abstract | errata | .bib | project page | code | video examples | test materials | slides | video presentation ]
-
Patrik Jonell, Taras Kucherenko, Gustav Eje Henter, and Jonas Beskow (2020)
Let's face it: Probabilistic multi-modal interlocutor-aware generation of facial gestures in dyadic settings
Proc. IVA 2020 (article no. 31, pp. 1–8)
Best Paper Award (given to 1 of 137 full paper submissions)
[ postprint | publisher | arXiv | abstract | .bib | project page | database | code | video examples | intro video | video presentation ]
-
Simon Alexanderson, Éva Székely, Gustav Eje Henter, Taras Kucherenko, and Jonas Beskow (2020)
Generating coherent spontaneous speech and gesture from text
Extended abstract in Proc. IVA 2020 (article no. 1, pp. 1–3)
Most downloaded paper in the IVA 2020 online proceedings as of 2021
[ postprint | publisher | arXiv | abstract | .bib | project page | listening examples (TTS part) | code (gesture part) | intro video ]
-
Anubhab Ghosh, Antoine Honoré, Dong Liu, Gustav Eje Henter, and Saikat Chatterjee (2020)
Robust classification using hidden Markov models and mixtures of normalizing flows
Proc. MLSP 2020 (pp. 1–6)
[ postprint | publisher | arXiv | abstract | .bib | slides | video presentation (paywalled) | journal paper ]
-
Simon Alexanderson and Gustav Eje Henter (2020)
Robust model training and generalisation with Studentising flows
Proc. 2nd workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models (INNF+) 2020 (article no. 25, pp. 1–9)
[ postprint | publisher (open access) | arXiv | abstract | .bib | slides | video presentation ]
-
Éva Székely, Gustav Eje Henter, Jonas Beskow, and Joakim Gustafson (2020)
Breathing and speech planning in spontaneous speech synthesis
Proc. ICASSP 2020 (pp. 7649–7653)
[ postprint | publisher | abstract | .bib | listening examples ]
-
Oliver Watts, Gustav Eje Henter, Jason Fong, and Cassia Valentini-Botinhao (2019)
Where do the improvements come from in sequence-to-sequence neural TTS?
Proc. SSW 2019 (pp. 217–222)
[ postprint | publisher (open access) | abstract | .bib | code | listening examples | test materials | slides ]
-
Éva Székely, Gustav Eje Henter, Jonas Beskow, and Joakim Gustafson (2019)
How to train your fillers: uh and um in spontaneous speech synthesis
Proc. SSW 2019 (pp. 245–250)
[ postprint | publisher (open access) | abstract | .bib | listening examples | poster ]
-
Petra Wagner, Jonas Beskow, Simon Betz, Jens Edlund, Joakim Gustafson, Gustav Eje Henter, Sébastien Le Maguer, Zofia Malisz, Éva Székely, Christina Tånnander, and Jana Voße (2019)
Speech synthesis evaluation – State-of-the-art assessment and suggestion for a novel research program
Proc. SSW 2019 (pp. 105–110)
[ postprint | publisher (open access) | abstract | .bib | slides ]
-
Éva Székely, Gustav Eje Henter, Jonas Beskow, and Joakim Gustafson (2019)
Spontaneous conversational speech synthesis from found data
Proc. Interspeech 2019 (pp. 4435–4439)
[ postprint | publisher (open access) | abstract | .bib | listening examples | poster ]
-
Éva Székely, Gustav Eje Henter, Jonas Beskow, and Joakim Gustafson (2019)
Off the cuff: Exploring extemporaneous speech delivery with TTS
Show & tell paper in Proc. Interspeech 2019 (pp. 3687–3688)
Best Show and Tell Paper award (given to 1 of 37 demos presented at the conference)
[ postprint | publisher (open access) | abstract | .bib | Show & Tell demo video | poster ]
-
Zofia Malisz, Gustav Eje Henter, Cassia Valentini-Botinhao, Oliver Watts, Jonas Beskow, and Joakim Gustafson (2019)
Modern speech synthesis for phonetic sciences: a discussion and an evaluation
Proc. ICPhS 2019 (pp. 487–491)
[ postprint | publisher (open access) | PsyArXiv | abstract | erratum | .bib | test materials | slides w/ audio (2.6 MiB) | slides w/o audio ]
-
Taras Kucherenko, Dai Hasegawa, Gustav Eje Henter, Naoshi Kaneko, and Hedvig Kjellström (2019)
Analyzing input and output representations for speech-driven gesture generation
Proc. IVA 2019 (pp. 97–104)
[ postprint | publisher | arXiv | abstract | .bib | project page | code (for Japanese) | code (for English) | slides | video presentation | English-language example | journal paper ]
-
Éva Székely, Gustav Eje Henter, and Joakim Gustafson (2019)
Casting to corpus: Segmenting and selecting spontaneous dialogue for TTS with a CNN-LSTM speaker-dependent breath detector
Proc. ICASSP 2019 (pp. 6925–6929)
[ postprint | publisher | abstract | .bib | poster ]
-
Taras Kucherenko, Dai Hasegawa, Naoshi Kaneko, Gustav Eje Henter, and Hedvig Kjellström (2019)
On the importance of representations for speech-driven gesture generation
Extended abstract in Proc. AAMAS 2019 (pp. 2072–2074)
[ postprint | publisher | abstract | .bib | project page | poster | full paper ]
-
Gustav Eje Henter, Jaime Lorenzo-Trueba, Xin Wang, Mariko Kondo, and Junichi Yamagishi (2018)
Cyborg speech: Deep multilingual speech synthesis for generating segmental foreign accent with natural prosody
Proc. ICASSP 2018 (pp. 4799–4803)
[ postprint | publisher | abstract | .bib | slides w/o audio ]
-
Jaime Lorenzo-Trueba, Gustav Eje Henter, Shinji Takaki, Junichi Yamagishi, Yosuke Morino, and Yuta Ochiai (2017)
Investigating different representations for modeling multiple emotions in DNN-based speech synthesis
Proc. 3rd International Workshop on Affective Social Multimedia Computing (ASMMC) 2017
[ postprint | abstract | .bib | journal paper ]
-
Gustav Eje Henter, Jaime Lorenzo-Trueba, Xin Wang, and Junichi Yamagishi (2017)
Principles for learning controllable TTS from annotated and latent variation
Proc. Interspeech 2017 (pp. 4799–4803)
[ corrected postprint | publisher (open access) | abstract | erratum | .bib | poster ]
-
Jaime Lorenzo-Trueba, Cassia Valentini-Botinhao, Gustav Eje Henter, and Junichi Yamagishi (2017)
Misperceptions of the emotional content of natural and vocoded speech in a car
Proc. Interspeech 2017 (pp. 606–610)
[ postprint | publisher (open access) | abstract | .bib ]
-
Hieu-Thi Luong, Shinji Takaki, Gustav Eje Henter, and Junichi Yamagishi (2017)
Adapting and controlling DNN-based speech synthesis using input codes
Proc. ICASSP 2017 (pp. 4905–4909)
[ postprint | publisher | abstract | .bib | listening examples ]
-
Srikanth Ronanki, Oliver Watts, Simon King, and Gustav Eje Henter (2016)
Median-based generation of synthetic speech durations using a non-parametric approach
Proc. SLT 2016 (pp. 686–692)
[ postprint | publisher | arXiv | abstract | .bib | poster ]
-
Takenori Yoshimura, Gustav Eje Henter, Oliver Watts, Mirjam Wester, Junichi Yamagishi, and Keiichi Tokuda (2016)
A hierarchical predictor of synthetic speech naturalness using neural networks
Proc. Interspeech 2016 (pp. 342–346)
[ postprint | publisher (open access) | abstract | .bib | poster ]
-
Srikanth Ronanki, Gustav Eje Henter, Zhizheng Wu, and Simon King (2016)
A template-based approach for speech synthesis intonation generation using LSTMs
Proc. Interspeech 2016 (pp. 2463–2467)
[ postprint | publisher (open access) | abstract | .bib | code | test materials | slides ]
-
Mirjam Wester, Oliver Watts, and Gustav Eje Henter (2016)
Evaluating comprehension of natural and synthetic conversational speech
Proc. Speech Prosody 2016 (pp. 736–740)
[ postprint | publisher (open access) | abstract | .bib | test materials | poster ]
-
Gustav Eje Henter, Srikanth Ronanki, Oliver Watts, Mirjam Wester, Zhizheng Wu, and Simon King (2016)
Robust TTS duration modelling using DNNs
Proc. ICASSP 2016 (pp. 5130–5134)
[ postprint | publisher | abstract | .bib | listening examples | test materials | slides w/ audio (2.0 MiB) | slides w/o audio ]
-
Oliver Watts, Gustav Eje Henter, Thomas Merritt, Zhizheng Wu, and Simon King (2016)
From HMMs to DNNs: where do the improvements come from?
Proc. ICASSP 2016 (pp. 5505–5509)
[ postprint | publisher | abstract | .bib | test materials | poster ]
-
Rasmus Dall, Sandrine Brognaux, Korin Richmond, Cassia Valentini-Botinhao, Gustav Eje Henter, Julia Hirschberg, Junichi Yamagishi, and Simon King (2016)
Testing the consistency assumption: Pronunciation variant forced alignment in read and spontaneous speech synthesis
Proc. ICASSP 2016 (pp. 5155–5159)
[ postprint | publisher | abstract | .bib | test materials | slides ]
-
Mirjam Wester, Cassia Valentini-Botinhao, and Gustav Eje Henter (2015)
Are we using enough listeners? No! An empirically-supported critique of Interspeech 2014 TTS evaluations
Proc. Interspeech 2015 (pp. 3476–3480)
[ postprint | publisher (open access) | abstract | .bib | slides ]
-
Gustav Eje Henter, Thomas Merritt, Matt Shannon, Catherine Mayo, and Simon King (2014)
Measuring the perceptual effects of modelling assumptions in speech synthesis using stimuli constructed from repeated natural speech
Proc. Interspeech 2014 (pp. 1504–1508)
[ postprint | publisher (open access) | abstract | .bib | database | listening examples | poster | slides w/ audio (2.9 MiB) | slides w/o audio ]
-
Matthew P. Aylett, Rasmus Dall, Arnab Ghoshal, Gustav Eje Henter, and Thomas Merritt (2014)
A flexible front-end for HTS
Proc. Interspeech 2014 (pp. 1283–1287)
[ postprint | publisher (open access) | abstract | .bib | .odp slides ]
-
Petko N. Petkov, W. Bastiaan Kleijn, and Gustav Eje Henter (2012)
Enhancing subjective speech intelligibility using a statistical model of speech
Proc. Interspeech 2012 (pp. 166–169)
[ postprint | publisher (open access) | abstract | .bib | poster | journal paper ]
-
Petko N. Petkov, W. Bastiaan Kleijn, and Gustav Eje Henter (2012)
Speech intelligibility enhancement using a statistical model of clean speech
Proc. The Listening Talker Workshop (p. 77)
[ postprint | .bib ]
-
Gustav Eje Henter, Marcus R. Frean, and W. Bastiaan Kleijn (2012)
Gaussian process dynamical models for nonparametric speech representation and synthesis
Proc. ICASSP 2012 (pp. 4505–4508)
[ postprint | publisher | abstract | .bib | poster ]
-
Gustav Eje Henter and W. Bastiaan Kleijn (2011)
Intermediate-state HMMs to capture continuously-changing signal features
Proc. Interspeech 2011 (pp. 1817–1820)
[ postprint | publisher (open access) | abstract | .bib | poster ]
-
Gustav Eje Henter and W. Bastiaan Kleijn (2010)
Simplified probability models for generative tasks: a rate-distortion approach
Proc. EUSIPCO 2010 (pp. 1159–1163)
[ postprint | publisher (open access) | abstract | .bib | poster | journal paper ]
{kind=link}
{kind=link}
{kind=link}
Conference contributions (not peer reviewed)
-
Taras Kucherenko, Patrik Jonell, Youngwoo Yoon, Pieter Wolfert, Zerrin Yumak, and Gustav Eje Henter (2021)
GENEA Workshop 2021: The 2nd workshop on generation and evaluation of non-verbal behaviour for embodied agents
Extended abstract in Proc. ICMI 2021 (pp. 872–873)
[ postprint | publisher | abstract | .bib | workshop page ]
-
Taras Kucherenko,* Patrik Jonell,* Youngwoo Yoon,* Pieter Wolfert, and Gustav Eje Henter (2020)
The GENEA Challenge 2020: Benchmarking gesture-generation systems on common data
Proc. GENEA (Generation and Evaluation of Non-verbal Behaviour for Embodied Agents) Workshop 2020
[ postprint | publisher (open access) | abstract | .bib | project page | data releases | slides (w/o video) | video presentation | newer paper ]
-
Krister Håkansson, Jonas Beskow, Hedvig Kjellström, Joakim Gustafsson, Alexandre Bonnard, Marie Rydén, Sara Stormoen, Göran Hagman, Ulrika Akenine, Kristal Morales Pérez, Gustav Eje Henter, Maria Sundell, and Miia Kivipelto (2020)
Robot-assisted detection of subclinical dementia: Progress report and preliminary findings
Alzheimer's & Dementia (vol. 16, no. S6, article e043311)
Presented at Alzheimer's Association International Conference (AAIC) 2020
[ preprint | publisher (open access) | conference | abstract | .bib | journal paper ]
-
Zofia Malisz, Gustav Eje Henter, Cassia Valentini-Botinhao, Oliver Watts, Jonas Beskow, and Joakim Gustafson (2019)
Modern speech synthesis and its implications for speech sciences
Proc. UK Speech 2019 (pp. 11–12)
[ abstract | publisher (open access) | .bib | slides w/ audio (2.6 MiB) | slides w/o audio ]
-
Éva Székely, Gustav Eje Henter, Jonas Beskow, and Joakim Gustafson (2019)
Spontaneous conversational TTS from found data
Proc. UK Speech 2019 (p. 31)
[ abstract | publisher (open access) | .bib | poster ]
-
Oliver Watts, Gustav Eje Henter, Jason Fong, and Cassia Valentini-Botinhao (2019)
Sequence-to-sequence neural TTS: an assessment of the contribution of various ingredients
Proc. UK Speech 2019 (p. 64)
[ abstract | publisher (open access) | .bib | poster ]
-
Zofia Malisz, Gustav Eje Henter, Cassia Valentini-Botinhao, Oliver Watts, Jonas Beskow, and Joakim Gustafson (2019)
The speech synthesis phoneticians need is both realistic and controllable
Proc. FONETIK 2019 (pp. 103–107)
[ postprint | publisher (open access) | abstract | .bib | slides ]
-
Éva Székely, Gustav Eje Henter, Jonas Beskow, and Joakim Gustafson (2019)
Spontaneous conversational speech synthesis: The making of a podcast voice – breathing, uhs & ums and some ponderings about appropriateness
Show & tell at FONETIK 2019 (without paper)
[ slides | .bib ]
-
Gustav Eje Henter, Jaime Lorenzo-Trueba, Xin Wang, Mariko Kondo, and Junichi Yamagishi (2018)
Generating segment-level foreign-accented synthetic speech with natural speech prosody
IPSJ SIG Technical Reports (vol. 2018-SLP-120, no. 8, pp. 1–3)
[ postprint | publisher | abstract | .bib | slides ]
-
Jaime Lorenzo-Trueba, Gustav Eje Henter, Shinji Takaki, and Junichi Yamagishi (2017)
Analyzing the impact of including listener perception annotations in RNN-based emotional speech synthesis
IPSJ SIG Technical Reports (vol. 2017-SLP-119, no. 8, pp. 1–2)
[ publisher | abstract | .bib ]
-
Gustav Eje Henter, Srikanth Ronanki, Oliver Watts, and Simon King (2017)
Non-parametric duration modelling for speech synthesis with a joint model of acoustics and duration
IEICE Technical Report (vol. 116, no. 414, pp. 11–16)
[ postprint | publisher | abstract | .bib | slides ]
-
Gustav Eje Henter, Srikanth Ronanki, Oliver Watts, Mirjam Wester, Zhizheng Wu, and Simon King (2016)
Robust text-to-speech duration modelling with a deep neural network
Proc. ASA/ASJ 2016 (vol. 140, no. 4, p. 2961)
[ abstract | publisher | .bib | poster ]
-
Gustav Eje Henter, Srikanth Ronanki, Oliver Watts, Mirjam Wester, Zhizheng Wu, and Simon King (2016)
Robust text-to-speech duration modelling using DNNs
Proc. UK Speech 2016 (p. 44)
[ postprint | publisher (open access) | abstract | .bib | poster ]
-
Srikanth Ronanki, Gustav Eje Henter, Zhizheng Wu, and Simon King (2016)
A template-based approach for intonation generation using LSTMs
Proc. UK Speech 2016 (p. 22)
[ postprint | publisher (open access) | abstract | .bib | poster ]
-
Gustav Eje Henter, Thomas Merritt, Matt Shannon, Catherine Mayo, and Simon King (2014)
Measuring the perceptual effects of speech synthesis modelling assumptions
Proc. UK Speech 2014 (p. 37)
[ abstract | publisher (open access) | .bib | poster ]
Preprints
-
Shivam Mehta, Éva Székely, Jonas, Beskow, and Gustav Eje Henter (2021)
Neural HMMs are all you need (for high-quality attention-free TTS)
Online preprint first posted Sept. 2021 (5 pages)
[ preprint | arXiv | abstract | .bib | code | listening examples ]
-
Taras Kucherenko, Rajmund Nagy, Michael Neff, Hedvig Kjellström, and Gustav Eje Henter (2021)
Multimodal analysis of the predictability of hand-gesture properties
Online preprint first posted Aug. 2021 (10 pages)
[ preprint | arXiv | abstract | .bib | project page ]
-
Anubhab Ghosh, Antoine Honoré, Dong Liu, Gustav Eje Henter, and Saikat Chatterjee (2021)
Normalizing flow based hidden Markov models for classification of speech phones with explainability
Online preprint first posted July 2021 (12 pages)
[ preprint | arXiv | abstract | .bib ]
-
Seyyed Saeed Sarfjoo, Xin Wang, Gustav Eje Henter, Jaime Lorenzo-Trueba, Shinji Takaki, and Junichi Yamagishi (2019)
Transformation of low-quality device-recorded speech to high-quality speech using improved SEGAN model
Online preprint first posted Nov. 2019 (5 pages)
[ preprint | arXiv | abstract | .bib | database | code ]
-
Gustav Eje Henter, Jaime Lorenzo-Trueba, Xin Wang, and Junichi Yamagishi (2018)
Deep encoder-decoder models for unsupervised learning of controllable speech synthesis
Online preprint first posted July 2018 (17 pages)
[ preprint | arXiv | abstract | .bib ]
-
Sang Phan, Gustav Eje Henter, Yusuke Miyao, and Shin'ichi Satoh (2017)
Consensus-based sequence training for video captioning
Online preprint first posted Dec. 2017 (11 pages)
[ preprint | arXiv | abstract | .bib | code ]
-
Gustav Eje Henter, Arne Leijon, and W. Bastiaan Kleijn (2016)
Kernel density estimation-based Markov models with hidden state
Online preprint first posted July 2018 (14 pages)
[ preprint | arXiv | abstract | .bib | slides ]
Theses
-
Gustav Eje Henter, supervised by W. Bastiaan Kleijn and Arne Leijon (2013)
Probabilistic sequence models with speech and language applications
Ph.D. thesis, School of Electrical Engineering, KTH Royal Institute of Technology
[ official record | abstract | introduction | .bib ]
-
Gustav Eje Henter, supervised by Jani Ekonoja and examined by Jan Grandell (2007)
Mathematical techniques for applied demand estimation and profit maximization
M.Sc. thesis, Department of Mathematical Statistics, KTH Royal Institute of Technology
* Asterisks signify equal contribution.
Note: Some audio files have been removed from the slides and presentations on this page due to strict Japanese regulations regarding personal data. Audio playback from pdf is known to work in Adobe Acrobat Reader (from trusted documents), but not in Preview on macOS.
This page was last updated 2021-11-22.
[ back to the top of the page | return to main page | contact the author ]
❧