Design
Indata till designen är kravspecen som den uttrycks i
de modeller som skapades under analys. Syftet
med design är att tänka igenom hela det avsnitt av koden som
ska konstrueras och att skapa en tydlig bild av hur koden ska struktureras.
De klasser, metoder osv som finns i designmodellen är tänkta att
finnas i koden också.
Design är en väldigt viktig aktivitet för att
få en genomtänkt kod. Det är också en relativt
svår aktivitet som mycket handlar om erfarenhet. Här är
centrala delar av "designkunskaperna" sammanfattade i några viktiga
principer och designmönster.
Just eftersom design är så viktig måste vi komma
ihåg att det inte ska vara mer än "en stunds eftertanke för
att komma mer rätt från början". Designen kommer aldrig
att bli så bra att kodningen blir en rent mekanisk översättning
av diagrammen till källkodsfiler. Mycket av det som finns i designmodellen
kommer att ändras vid kodning. Det är knappast meningsfullt
att ägna mer än en halv dag åt design i en enveckas iteration.
Designens grundprinciper
Det här är väldigt långt ifrån en fullständig
kurs i objektorienterad design, vi tar bara en kort titt på några
av de allra viktigaste principerna. Först av allt, syftet:
Det ska vara lätt att ändra programmets beteende och att
utöka dess funktionalitet, detta ska kunna göras utan att behöva
ändra i befintlig kod.
Når vi dit kan programmet leva länge utan att koden
degenererar till en ounderhållbar gröt som ingen vågar
ändra i.
Definition - Implementation
Definitionen är det som andra objekt kan se, tex namn på
klasser och interface och signaturer för publika metoder. Implementationen
är till exempel privata metoder och koden som publika metoder innehåller.
Ingenting får vara beroende av implementationen, det enda som ska
användas av andra objekt är definitionen. På så sätt
är det möjligt att ändra i implementationen utan att påverka
någon annan kod än den som ändras. Betrakta detta lilla
exempel från collection-API:et i paketet java.util:
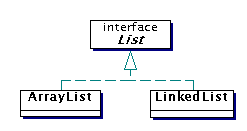 List är ett interface som innehåller definitioner
av metoder för en lista. ArrayList och LinkedList är klasser
som innehåller helt olika implementationer av en lista, dvs helt
olika kod. Låt oss nu anta att något objekt använder en
lista på det här sättet:
List är ett interface som innehåller definitioner
av metoder för en lista. ArrayList och LinkedList är klasser
som innehåller helt olika implementationer av en lista, dvs helt
olika kod. Låt oss nu anta att något objekt använder en
lista på det här sättet:
List list = new ArrayList();
list.add(obj);
list.get(2);
//en massa andra operationer på listan.
Helt plötsligt kommer vi på att det var dåligt
att använda ArrayList, vi borde ha en LinkedList
i stället. Det enda som behöver göras är att ändra
första raden till List list = new LinkedList(). Detta innebär
att en helt annan kod (implementationen) kommer att exekveras men tack
vara att vi bara refererade till interfacet List (definitionen)
krävde det nästan ingen alls förändring av koden! Interface
borde användas på detta sätt i mycket större utsträckning
än vad som är fallet!
Detta resonemang gäller även på andra nivåer,
vi kan till exempel ha ett paket med bara en publik klass (en sådan
klass brukar kallas fasad). Dess publika gränssnitt utgör då
paketets definition och alla andra klasser i paketet utgör dess implementation.
Det är ofta ofarligt att ändra en implementation men livsfarligt
att ändra en definition eftersom det kan finnas väldigt många
beroenden av den.
Inkapsling
Enligt resonemanget ovan är viktigt att ha en stabil definition.
Exakt vad är det då som utgör definitionen av till exempel
en klass? Jo, det är allting som någonting utanför klassen
kan se, dvs klassens namn samt signaturen av dess publika variabler, metoder
samt inre klasser och interface (dvs dess publika gränssnitt). Desto
mindre denna definition är desto lättare är det hålla
den stabil. Alltså bör klassen ha få publika metoder
och helst inga publika variabler alls.
Hur är det då med klasser, metoder osv som är protected
eller paketprivata? Protected behöver väldigt sällan användas
så det hoppar vi över. Paketprivat åtkomst är däremot
mycket vanlig. Den är mycket närmre besläktad med privat
åtkomst än med publik. Låt oss anta att vi ska utveckla
en viss begränsad funktionalitet, till exempel hantering av ett bankkonto
(inte av ett helt banksystem utan bara av ett konto). Vi inser att det
finns olika typer av konton, olika räntor osv varför det inte
räcker med en enda klass. Vi utvecklar då ett kontopaket istället
för en kontoklass. Detta kontopaket blir en mycket väl sammanhållen
enhet med ett tydligt publikt gränssnitt. För tydlighets skull
råkar paketet innehålla mer än en klasser. Att dessa klasser
anropar varandras metoder (paketprivat åtkomst) är dock ett
relativt ofarligt beroende eftersom de är en så väl sammanhållen
enhet. Detta resonemang håller inte alltid till fullo eftersom ett
pakets innehåll inte alltid är så väl sammanhållet.
Det viktigaste är dock att begränsa den publika åtkomsten
även om privat i och för sig är bättre än paketprivat.
Protected undviker vi om vi inte vet mycket väl varför vi ska
ha det.
En annan aspekt av inkapsling är att variabler helst alltid
ska vara privata, ovanstående resonemang gäller främst
allt utom variabler. Anledningen till att variabler ska vara privata är
att om de accessas uteslutande via metoder i klassen har vi full koll på
hur de accessas. Vi kan till exempel i metoderna utföra omvandlingar
mellan enheter, utföra säkerhetskoller, göra typkonverteringar
osv. Att accessa variabler via metoder gör också koden robustare.
Om vi till exempel vill byta typ på variabeln behöver vi inte
byta typ på det publika gränssnittet i metoden som accessar den.
Vi har också möjlighet att till exempel synkronisera access av
variabeln om det helt plötsligt skulle bli nödvändigt.
Hög sammanhållning (high cohesion)
En klass ska ha väldefinierad kunskap och en väldefinierad
uppgift. En klass Anställd ska till exempel inte innehålla
en massa information om företaget den anställde jobbar på.
Den kan i stället ha en referens till en klass Företag som innehåller
den informationen.
Vidare ska klasser bara innehålla metoder som är relaterade
till det klassen representerar. Klassen Anställd ska till exempel
innehålla metoder som hanterar dess namn och adress och vilket företag
den jobbar på, medans klassen Företag ska innehålla metoder
som hanterar till exempel lönehantering för den anställde.
En slutsats av detta blir att det är viktigt att dela upp klasser.
Det är bara alltför vanligt att program innehåller för
få och för stora klasser som har för mycket och för
oklar kod som snart blir grötig och svårunderhållen.
Låg koppling (low coupling)
Klasser ska ha litet beroende av andra klasser, dvs de ska inte
i onödan anropa metoder på andra klasser eftersom koden i
dem då påverkas av ändringar av koden i de anropade
klasserna. Olika typer av beroenden är dock olika farliga. Det är
till exempel ofarligt att använda klasserna i paketen java.*
som levereras med J2SE eftersom dessa klasser är extremt stabila.
Mer generellt är ett beroende ofarligare ju stabilare den anropade
klassen är. Vidare är det ofarligare med ett beroende av en klass
i samma paket än av en klass i ett annat paket eftersom vi har större
koll på klassen i samma paket. Desto större koll vi har på
klassen vi är beroende av detso ofarligare är beroendet.
Några fler tips (patterns)
Kanske inte direkt designens grundprinciper men vanliga lösningar
på vanliga problem
Controller
Problem
Vart ska ett system event (anropen från aktören i SSD)
ske? Vem ska hantera dem?
Lösning
Klasser som har detta ansvar kallas controller.
Vi kommer huvudsalkigen att använda klasser (eller metoder
i klasser) som representerar scenarion i ett use case. Det är bra
(för tydlighets skull om namnet på use case:t finns med i
namnet på metoden (om det är en metod per use case/scenario)
eller klassen (om det är en klass per use case/scenario). Denna
variant kallas use case controller.
En annan lösning är att inte associera controllern med
scenarion utan med en del av programmet (tex ett paket). Klassen hanterar
då all användning av subsystemet oavsett scenario. Detta kallas
en facade controller.
Observera att en controller aldrig ska vara en del av användarggränssnittet.
Creator
Problem
Vem ska skapa nya instanser av klasser?
Lösning
Det är lämpligt att A skapar instanser av B om
- A innehåller objekt av B
- A bokför objekt av B (A är till exempel någon
typ av rapport).
- A har hög koppling med B
- A har det data som krävs för att initiera en instans
av B.
Arkitektur
Arkitekturen är systemets "skelett", hur det ser ut i stora
drag. Arkitekturen talar inte om hur problem löses, snarare
att de kan lösas och var de löses. Den växer
egentligen fram under iterationerna i eleboration. I vårt fall
är dock ganska mycket givet: J2EE, uPortal, EJB:er, PostgreSQL, JBoss,
SPARC-Solaris samt hårdvaran. Jag har dessutom tagit mig friheten
att på egen hand gå vidare med arkitekturen. Vad är detta?!?
Diktatur! Vattenfallsprocess!! Möjligen det första, men projektet
är stort nog ändå. Den lösning jag skissar är
på intet sätt kontroversiell, det är en typisk J2EE-struktur.
Jag har fråntagit er glädjen att läsa en massa om J2EE
best practises och upptäcka en massa tjusiga mönster att välja
bland. Problemet är att det tar minst ett år att sjunka in ordentligt
i J2EE och dessutom hade ni förmodligen kommit fram till en likartad
lösning ändå. Vattenfallsprocess är det däremot
inte. En process lever inte för sin egen skull. Efter att ha gjort
en massa olika projekt med samma teknologi får man helt naturligt
en känsla för en lämplig arkitektur. Då ska man naturligtvis
inte vara rädd för att använda den trots att processen är
iterativ. Däremot måste man vara öppen för förändringar
och nya upptäckter. Jag har inte gjort en färdig kalender för
att kolla att det fungerar, upptäcker vi om några veckor att
arkitekturen inte håller måste vi vara beredda att ändra
den.
Skikt
Det första steget är att dela upp systemet i skikt.
Skikten blir alltid ungefär desamma när det handlar om webapplikationer
men det finns många olika namn på dem. Vi kallar dem Client
(browsern), Presentation (där vyerna konstrueras, i vårt fall
utgörs det av uPortal), Business (där all affärslogik hanteras,
i vårt fall EJB:erna), Integration (mappning mellan den objektorienterade
modellen i Business och relationsdatabasen i Resource) samt Resource (persistent
lagring,ivårt fall Postgres-databasen):

Observera att det bara finns beroenden av djupare liggande skikt.
Presentation
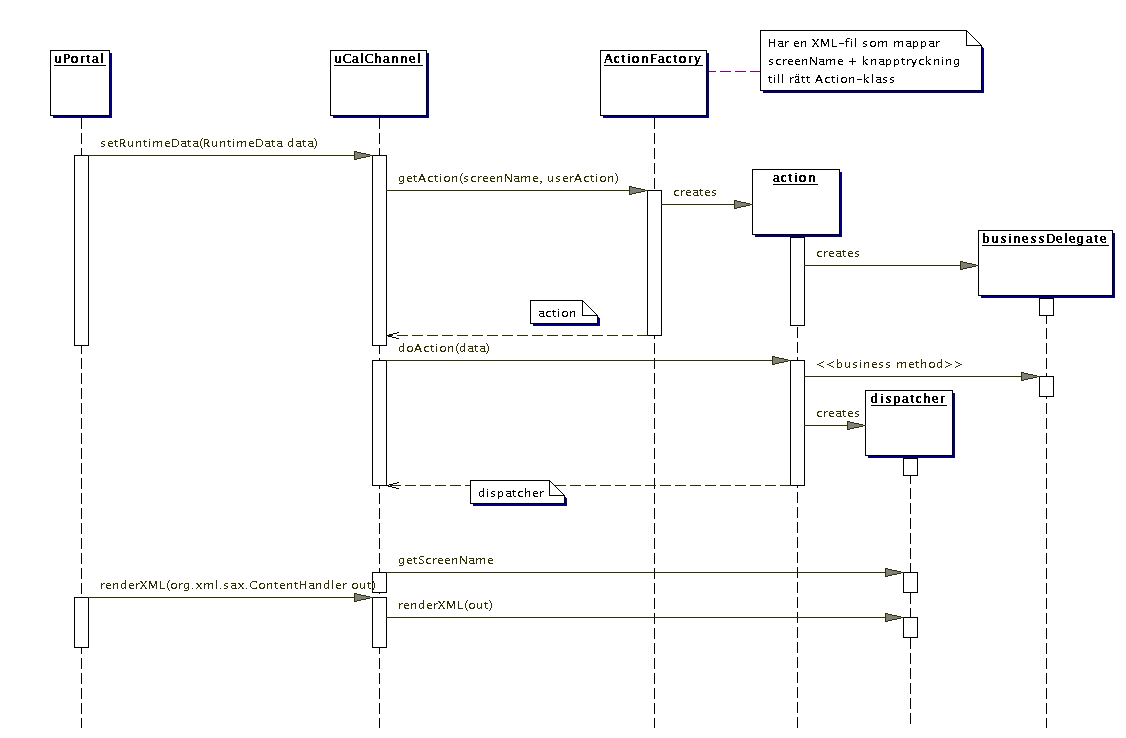
Det första skiktet vi tittar in i är presentation, dvs kanalen
i uPortal. Här bygger vi ett ramverk som kommer att göra det
lätt att utöka och ändra funktionaliteten. Idén är
att själva kanalklassen, UCalChannel, inte ska innehålla
någon flödeskontroll eller någon annan logik. Det är
i klasser som implementerar Action som själva arbetet utförs.
UCalChannel ber ActionFactory om en Action-klass
som kan utföra det arbete som krävs när en viss vy visas
och användaren har klickat på en viss knapp. Om till exempel
vyn boka möte visas ovh användaren klickar på OK kanske
en Action BookMeetingAction returneras som hanterar bokandet
av ett möte. ActionFactory väljer rätt Action
mha en XML-fil som kopplar vy+knapp till rätt Action-klass.
När en Action skapas skapar den en BusinessDelegate som är
en klass som innehåller alla anrop till business-skiktet (alltså
EJB:erna) för ett visst use case. På det viset har all kunskap
om business-skiktet isolerats i en klass. En Action har en metod
doAction som utför själva arbetet. Den returnerar en
Dispatcher-klass som ska hantera visandet av nästa vy. Dispatcher
kan dels tala om för UCalChannel vad nästa vy heter,
dels skapa den (i metoden renderXML). I diagrammet ser det ut som om namnet
på Dispatcher-klassen är hårkodat i Action-klassen.
Det är inte nödvändigt, det skulle lika gärna kunna
stå i ActionFactorys XML-fil.
Det tjusiga med denna lösning är att det enda som behöver
göras för att lägga till ny funktionalitet är att
skriva en ny Action, en ny Dispatcher och eventuellt
en ny BusinessDelegate samt att lägga till en rad i XML-filen. Den
befintliga koden påverkas inte alls!! Om någon funktionalitet
ska ändras är risken att påverka något annat än
det som ändras minimal eftersom allting är isolerat i en egen
Action och en egen Dispatcher.
Det var presentation i stort, nu tar vi en titt inuti några av
klasserna:
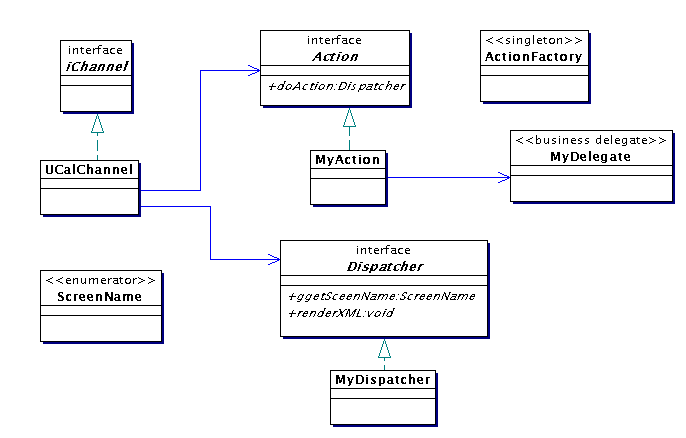
- ActionFactory
Detta är en singleton vilket innebär att det bara finns ett
objekt av den. Den ser ut ungefär så här:
class ActionFactory {
private static final ActionFactory instance = new ActionFactory();
private ActionFactory() {}
public getInstance() {
return instance();
}
...
Dessutom har den en metod getAction som läser
i XML-filen och returnerar ett objekt av rätt Action. Om
Action-objekten är tillståndslösa, dvs inte
har några instansvariabler (vilket de absolut inte bör ha)
behöver ActionFactory inte skapa nya objekt varje gång
utan kan cacha dem i en Map. På så sätt
behövs det bara skapas ett objekt av varje Action.
- UCalChannel
Den kod som ingår i ramverkat är något i den här
stilen:
ActionFactory actionFactory = ActionFactory.getInstance();
Dispatcher dispatcher;
ScreenName screenName;
public void setRuntimeData(ChannelRuntimeData data) {
dispatcher = actionFactory.getAction(screenName, userAction).doAction(data);
screenName = dispatcher.getScreenName();
}
public void renderXML(ContentHandler out) {
dispatcher.renderXML(out);
}
- ScreenName
Detta är en uppräkningsbar typ som finns för att vi
inte ska behöva skriva stränger som utgör namnen på
vyerna och riskera krångel pga felstavningar. Överallt där
namnet på en vy ska anges ska vi alltså använda konstanter
från ScreenName. En uppräkningsbar typ i Java ser
ut så här:
class ScreenName {
static final ScreenName MAIN_SCREEN
= new ScreenName();
static final ScreenName BOOK_MEETING_SCREEN = new ScreenName();
//names for all screens.
private ScreenName(){}
}
Business
I affärslogikskiktet behöver vi inte skriva något ramverk
eftersom EJB i sig är ett utordentligt ramverk. Däremot ska
vi använda EJB:erna enligt vissa väl beprövade designmönster.
Vi går igenom klasserna en itaget, skiktet business börjar med
klassen MyDelegate.
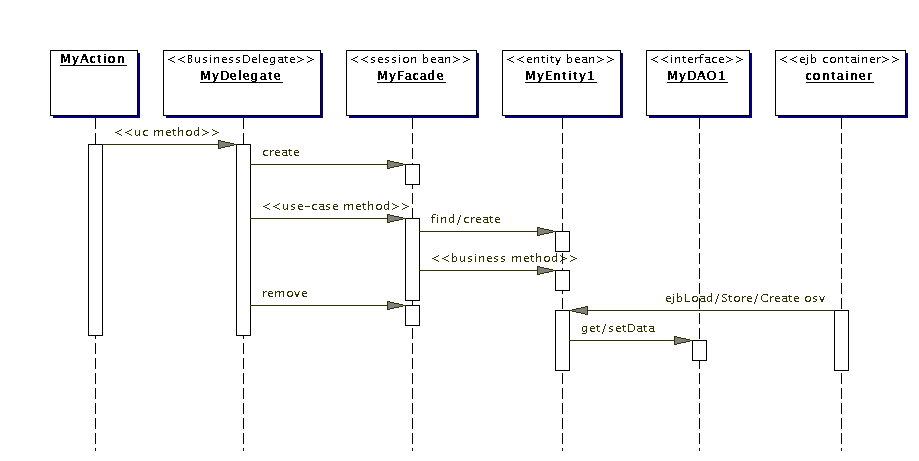
- MyDelegate
BusinessDelegate-klasserna agerar som proxy till sessionsbönorna.
Det finns en delegate per sessionsböna och de har förmodligen
exakt samma metoder som sin sessionsböna. Syftet är i första
hand att innehålla all kod som har med EJB:er att göra så
att den koden inte sprids ut lite överallt i presentation-skiktet.
En delegate MeetingHandlerDelegate som hanterar allt som har
med möten att göra skulle kunna se ut ungefär så här:
class MeetingHandlerDelegate {
MeetingHandlerHome meetingHandlerHome;
MeetingHandlerDelegate() {
meetingHandlerHome = //JNDI-uppslagning
av sessionsbönan MeetingHandlers home interface.
}
void bookMeeting(...) throws UCalendarException {
try {
MeetingHandler meetingHandler
= meetingHandlerHome.create();
meetingHandler.bookmeeting();
meetingHandler.remove();
catch (//all EJB related exceptions) {
throw new UCalendarException(...);
}
}
}
Detta fungerar bara om sessionsbönan ät tillståndslös
(vilket är att föredra). Om den inte är tillståndslös
blir det lite krångligare men det tar vi om behovet av tillståndsfulla
sessionsbönor dyker upp.
Egentligen ska en SessionFacade (se nedan) representera en aktör.
Vi borde alltså ha haft en sessionsböna User i stället
för MeetingHandler. Problemet är att vi har så
många use case som ska utföras av aktören user att jag
är rädd att den sessionsbönan skulle bli ohanterligt stor.
Därför får vi dela upp den på något sätt.
Min tanke här var att ha en SessionFacade som hanterar alla mötesrelaerade
use case men jag är inte alls säker på att det är
en lämplig uppdelning.
- MyFacade
Detta är en SessionFacade, dvs en sessionsböna som har hand
om flödeskontrollen för ett use case. Observera att vi aldrig
anropar entitetsbönorna direkt utan bara deras SessionFacade. Det är
enklast om den är tillståndslös och har en metod per use
case. Den metoden innehåller då flödeskontrollen för
allt som har med det use caset att göra, däremot gör den inget
av jobbet. Metoden kommer att påminna mycket om scenariona i use case-modellen.
Kommunikationen mellan en BusinessDelegate och en sessionsböna
sker över nätverket via RMI. Av prestandaskäl ska vi hålla
nere antalet nätverksanrop. Om BusinessDelegaten behöver hämta
mycket data är det därför olämpligt att ha metoder
i stil med getData1, getData2 osv. Istället gör
vi en metod, getData, som returnerar ett objekt vars enda syfte
är att inkapsla allt data (kallas ValueObject). Detta objekt skapas
av sessionsbönan, överförs till BusinessDelegaten som läser
dess innehåll, sedan används det inget mer.
- MyEntity
SessionFacaderna anropar i sin tur entitetsbönor. En entitetsböna
representerar en entitet, till exempel en rad i en databas. En entitetsböna
ska i första hand betraktas som den persistenta entitet den representerar,
inte som ett flyktigt javaobjekt. Konceptet entitetsbönor är
ett utmärkt sätt att skapa en objektorienterad bild av tex en
relationsdatabas och att koppla operationer (alltså metoder) till
entiteterna. Det ska finnas en entitetsböna per entitet (Möte,
Kontakt, Grupp, Adressbok osv). Det är helt OK att ha flera lager av
entitetsbönor, tex kan en entitetsböna Adressbok ha underliggande
entitetsbönor Kontakt och Grupp). Entitetsbönorna
får bara anropas av SessionFacader eller andra entitetsbönor.
De ska ha lokala interface, alltså inte remote interface
(av prestandaskäl).
- Tjänster (visas inte i diagrammen nedan)
Det finns tjänster som till exempel att logga eller att skicka
mail som varken är en SessionFacade eller en entitet. Dessa ska hanteras
av sessionsbönor som bara ska anropas av SessionFacader.
- MyDAO
Entitetsbönorna får inte innehålla någom SQL-kod,
det vore att bryta mot regeln om hög sammanhållning. En entitetsböna
är ansvarig för en entitet, inte för databasen. Började
vi skriva SQL lite överallt skulle enitetsbönorna snart bli
hemskt grötiga. Entitetsbönornas vy av databasen är istället
en eller flera DAO:er. Det kan vara lämpligt med en DAO per entitetsböna,
vi kan till exempel ha en klass MeetingDAO. Dess metoder ska
inte vara mappade på något sätt mot databasens tabeller
utan ska vara utformade så att de utför arbete entitetsbönan
har nytta av. DAO:n MeetingDAO kan till exempel ha dessa metoder
(MeetingVO är ett ValueObject, beskrivet under MySession,
som innehåller allt data om ett möte) :
MeetingVO getMeeting(<<primary key>>)
Collection getMeetingsWithContact(<<contact>>)
Collection getAllMeetings()
void createMeeting(MeetingVO)
void updateMeeting(MeetingVO)
DAO:erna hör egentligen till skiktet integration men
eftersom deras gränssnitt är orienterat mot entitetsbönorna
måste det skapas av de som skriver business-skiktet.
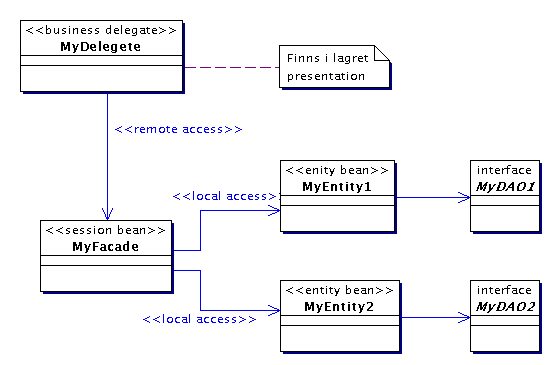
Integration
Skiktet integration består av DAO:er enligt vad som diskuterades
i stycket om business ovan. En DAO består dels av ett interface och
dels av en klass som implementerar det. Syftet är precis det som beskrevs
i stycket "definition-implementation" under "designens grundprinciper".
Interfacet innehåller definitionen som är helt oberoende av hur
sql-satserna ser ut, den är till och med oberoende av om det över
huvud taget finns några sql-satser. Implementationen (dvs klassen MyPostgresDAO
i diagrammet nedan) innehåller all kod som är relaterad till
en viss databashanterare (postgres i vårt fall). Det enda som händer
om vi byter databashanterare är att vi får skriva en ny klass
MyXXXDAO som används i stället för MyPostgresDAO. Interfacet
MyDAO påverkas inte alls och inte heller någon EJB. Är det
tjusigt eller är det tjusigt?
Design av ett use case
Efter denna blixtkurs i design och uCalendars arkitektur är
det dags att designa koden för use case:t överför pengar
mellan konton. Först tar vi itu med skiktet business.
Business
Vi börjar med att välja controller (dvs SessionFacade)
eftersom det är den som tar emot en operation som utförs på
detta skikt. Kandidater till Controller är klasser i domänmodellen
som kan anses hantera överföringen, till exempel Kassör och
Kassa. Vi väljer Kassa med tanken att alla use case som startas i
kassan ska hanteras av den SessionFacaden. Kan hända kommer det i framtiden
visa sig att det blir ohanterligt många use case, då får
vi dela på klassen Kassa men tills vidare har vi den som SessionFacade.
Scenariot vi ska implementera innehåller två systemoperationer,
startaOverforing och angeKontoOchBelopp, vilket skulle
innebära att klassen Kassa skulle ha dessa två metoder. När
det handlar om EJB finns det emellertid mycket att vinna på att ha
hela use case:t i en metod, nämligen att all flödeskontroll och
transaktionshantering kan ske i den samt att vi kan använda en stateless
sessionsböna (lättare och antagligen snabbare). Vi låter därför
operationen startaOverforing stanna i användargränssnittet,
den resulterar bara i att en ny skärmbild visas. Allt arbetet i modellen
utförs vid operationen angeKontoOchBelopp. Detta är dock
inget bra namn på en metod i en Controller, den ska i stället
heta något som antyder vilket use case det handlar om. Vi kallar den
helt enkelt overforing.
Det är bäst att använda ett interaction diagram för
att göra design. Förmodligen är ett collaboration diagram
överskådligast men jag är inte vän med mitt UML-verktyg
så det måste bli ett sequence diagram, se figuren nedan till
vänster:
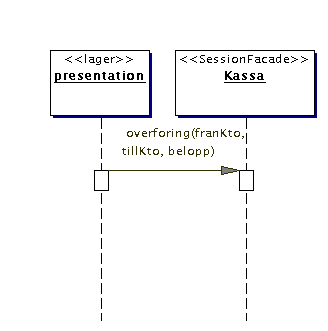
Det var sessionsbönan, nu tittar vi på entitetsbönorna.
En titt i domänmodelen säger oss att två konton ska uppdateras
(de som överföringen görs från och till). Dessa konton
är entiteter, dvs de finns redan i databasen. De är inte något
som sessionsbönan kassa skapar, den slår istället upp dem
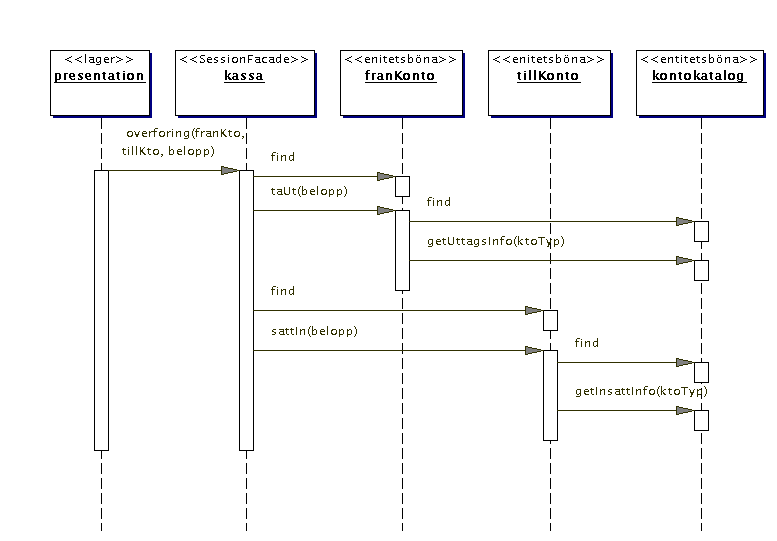
i databasen. Denna uppslagning hanteras av ejb-metoden find: 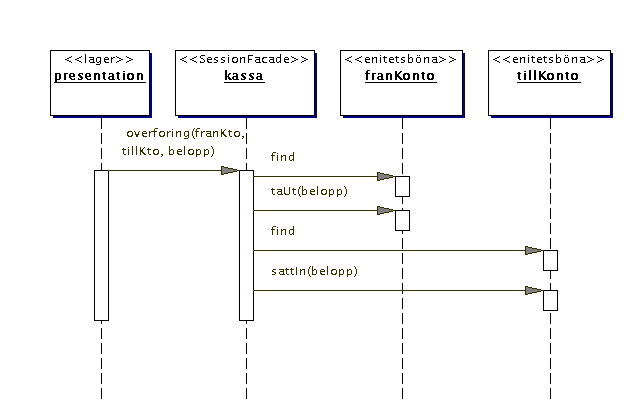
Nu kan vi misstänka att för att kunna hantera uttag och insättning
måste kontoeniteterna kolla i kontospecifikationen i kontokatalogen
om det till exempel ska dras någon uttagsavgift. Detta är kanske
inte sant i en riktig bank eftersom eventuella uttagsavgifter antagligen
beräknas när det är dags att beräkna räntan. Om
uttagsavgifter ska dras från kontot redan när uttaget sker kan
det se ut så här:
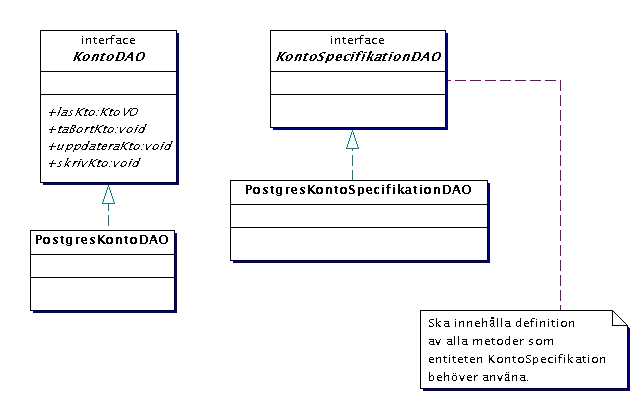
Kontokatalog kan i sin tur ha entiteter Kontospecifikation som innehåller
specifikationer för en viss typ av konto. Det tar jag inte med här
för att diagramet inte ska bli för stort. Notera bara att det
vore vödvändigt med samlingar av Kontospecifikation för varje
kontotyp eftersom det till exempel inte räcker att veta räntenivån
just nu, vi måste kunna ta reda på nivån vid alla tillfällen
under ett år för att kunna beräkna räntan vid årsskiftet.
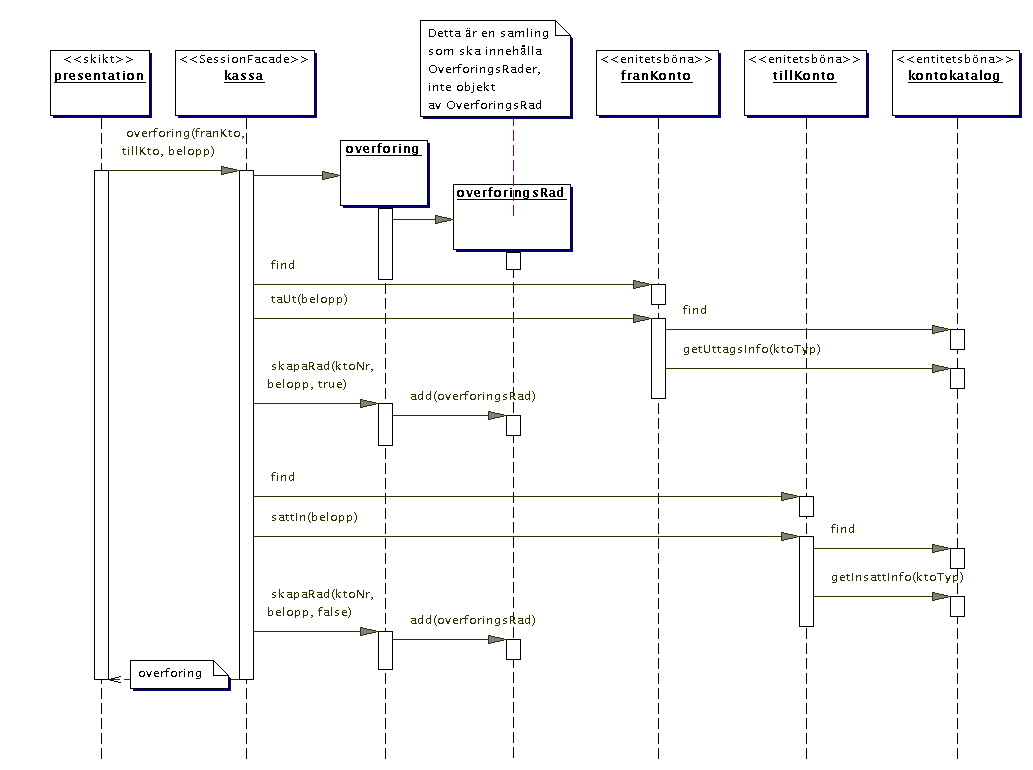
Nu funderar vi i stället på kvittot. Enligt SSD ska ett kvitto
returneras och enligt domänmodellen ska det inehålla objekt
av typen Overforing med objekt av typen OverforingsRad. Ska dessa vara
entiteter som sparas i databasen? Det beror på om vi vill kunna få
fram information om dem vid ett senare tillfälle. Vi antar nu att
så inte är fallet. Det ger oss tre val: Metoden overforing returnerar
kvittoinformationen, SessionFacaden (Kassa) görs till en tillståndsfull
sessionsbönasamt att kvittoinformationen skapas i skiktet presentation.
Det finns ingen anledning att gå igenom allt besvär med en tillståndsfull
sessionsböna bara för att kunna anropa en annan metod som ska
returnera kvittoinformationen, vilket lämnar oss två alternativ
kvar. Det finns för och nackdelar med båda två men vi väljer
att låta metoden overföring returnera informationen:
Slutligen konstaterar vi dels att det som i diagrammen ovan är ritat
som skiktet presentation i själva verket är en BusinessDelegate
som finns i presentation. Denna innehåller exakt samma metod som
SessionFacaden, overforing(franKto. tillKto, belopp). Vidare konstaterar
vi att alla entiteter ska ha varsin DAO. I diagrammet ritar jag (av utrymmesskäl)
bara ut DAO:n till en av kontoentiteterna:
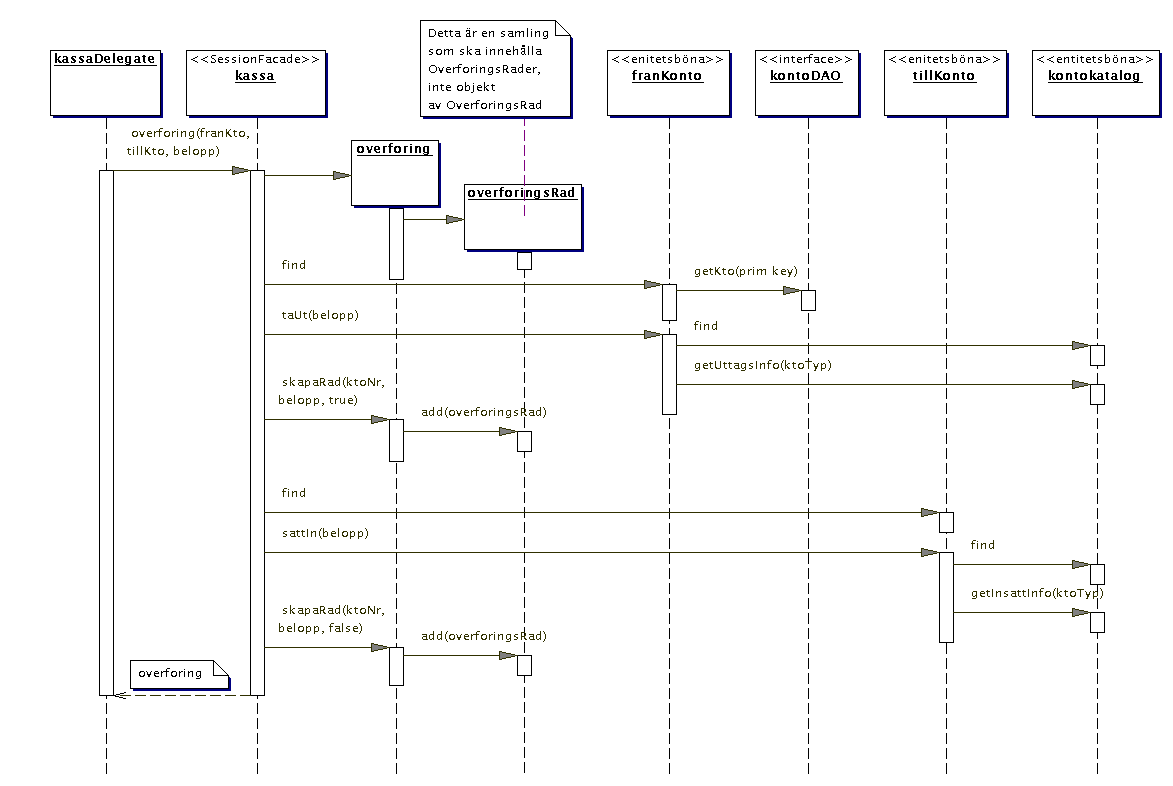
I diagrammet ovan har DAO:n bara en metod, det är dock inte sant.
Den måste också innehålla de metoder som krävs för
att hantera EJB-containerns anrop av ejbLoad, ejbStore osv. Som minimum
lär detta innebära metoderna updateKto(ktoVO), createKto(ktoVO)
samt deleteKto(prim key).
När vi nu är klara med sekvensdiagrammet för skiktet business
kan det vara bra att rita ett klassdiagram för detsamma:
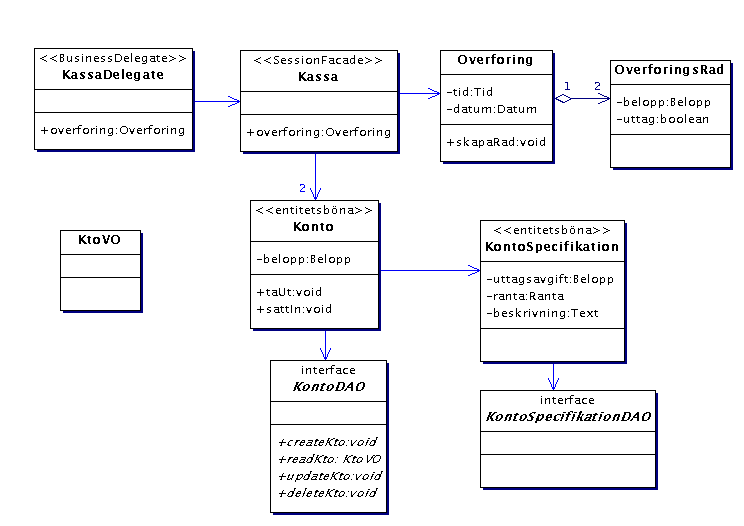
Några kommentarer om diagrammet ovan.
- Rita alltid ut rikting på associationer i ett klassdiagram.
- Rita inte ut onödigt mycket detaljer om metoder och attribut,
rita dock ut metodernas parametrar och deras typ.
- Rita inte ut set/get-metoder i onödan.
Ifall överföringen skulle loggas skulle vi införa en tjänst
"loggning" representerad av en tillståndslös sessionsböna
"logger" som hanterade all loggning. Den skulle anropas av Kassa.
Nu är designen av businss-skiktet klar. Nu kan tre olika aktiviteter
fortsätta parallellt: Koda business, designa och koda presentation
(kodning sker mha en BD som returnerar fejkade värden i stället
för att anropa business om business ännu inte är färdigkodat),
designa och implementera resource.
Resource
Här handlar det om att bestämma hur entiteterna ska lagras
i databasen. Domänmodellen och designmodellen för business-skiktet
talar om vad som ska sparas men absolut inte hur. Business
innehåller en objektorienterad modell av entiteterna men det säger
inget om hur en relationsdatabas med samma eniteter ska vara uppbyggd.
Jag är inte bra på att designa relationsdatabaser så
tyvärr kan jag inte ge några råd om det.
Integration
När både business och resource är designade går
det bra att designa och koda integration. Designen är ganska trivial:
Presentation
Slutligen är det dags att designa presentation. Tack vare ramverket
vi skrev räcker det med följande:
- En ny klass som implementerar Action, OverforingAction.
- En ny klass som implementerar Dispatcher, OverforingDispatcher.
- En ny rad i xml-filen som mappar den knapp som startar överföringen
till OverforingAction.
- Ytterligare några rader i xml-filen för allt användaren
kan göra i vyn som visas av OverforingDispatcher.
Undantag
Checked exceptions ska användas för alla fel som inte kan
upptäckas vid programmering. Det är till exempel att typiskt
checked exception att det inte finns tillräckligt mycket pengar på
ett konto för att kunna utföra ett uttag. Å andra sidan
är det ett typiskt unchecked exception att försöka läsa
på för högt index i en array. I det första fallet
ska vi kasta en egenutvecklas klass som ärver av Exception,
i det andra fallet kastas automatiskt ArrayIndexOutOfBoundsException
som ärver av RuntimeException.
Här kommer några enkla riktlinjer för hur undantag ska
användas:
- Undantagen ska ha namn som beskriver felet.
- Skapa inte onödigt många undantagsklasser. Finns det
många undantagsklasser finns det risk att metodsignaturer ändras
hela tiden när vi kommer på nya undantag. Det kan räcka med
en klass per "subsystem", tex kastar alla klasser i paketet java.sql undantaget
SQLException oavsett vilket fel som uppstod i databasen. Om vi använder
få klasser är det klokt att låta undantaget innehålla
tex en sträng som beskriver felet.
- Undantag ska inte propagera upp genom flera lager/skikt. Tex kan
databashanteringen i DAO:erna resultera i att ett SQLException kastas.
Detta måste fångas i DAO:n eftersom EJB:erna inte ska innehålla
någon databasrelaterad kod. När det fångats kan tex ett
EJBException kastas i stället för att meddela EJB:n att den anropade
metoden i DAO:n misslyckades. På samma sätt måste alla
EJBException och RemoteException fångas senast i BusinessDelegaten
och omvandlas till något undantag som kan hanteras i presentation.
- Många fel kan åtgärdas direkt men en del fel måste
ramla hela vägen upp till klienten och visas för användaren.
Ett annat subset av felen ska loggas. För dessa båda ändamål
är det lämpligt att ha (minst) en speciell Action och
(minst) en Dispatcher för felhantering. För att returnera
dessa kan vi ge ActionFactory en ny metod: getErrorAction(ScreenName,
Exception).
Paket
Hela diskussionerna som fördes om "low coupling - high cohesion"
och om inkapsling i avsnittet om designens grundprinciper gäller paket
precis lika väl som klasser. Det är viktigt att ett pakets publika
gränssnitt är stabilt, om ändringar sker inuti ett paket
är inte lika farligt. Desto fler beroenden det finns av ett paket,
desto stabilare måste det vara.
Vad gäller uCalendars börjar alla paketnamn med att identifiera
organisationen där de utvecklas:
se.kth.isk
Därefter kommer produktens namn:
se.kth.isk.ucalendar
Sedan kommer namnet på skiktet där paketet finns:
se.kth.isk.ucalendar.presentation
se.kth.isk.ucalendar.business
se.kth.isk.ucalendar.integration
Därefter gäller följande för de tre olika skikten:
Presentation
Ramverket placerar vi i ett eget paket:
se.kth.isk.ucalendar.presentation.framework
Action- och Dispatcher-klasser placeras i olika paket beroende på
funktionalitet, tex
se.kth.isk.ucalendar.presentation.meeting
se.kth.isk.ucalendar.presentation.note
Om det blir några generella klasser med "bra att ha"-metoder placerar
vi dem i ett eget paket:
se.kth.isk.ucalendar.presentation.util
Business och Integration
Här har vi inget ramverk så det blir bara paket i stil med
se.kth.isk.ucalendar.business.meeting
se.kth.isk.ucalendar.integration.meeting
och
se.kth.isk.ucalendar.business.util
se.kth.isk.ucalendar.integration.util
Tester
JUnit-tester läggs i ett paket test inuti det paket de testar. Tester
för klasser i tex paketet
se.kth.isk.ucalendar.business.meeting hamnar alltså i
ett paket se.kth.isk.ucalendar.business.meeting.test
Säkerhet
Authorization
Oavsett om vi kommer att använda olika rättigheter eller inte
ska uCalendar byggas med stöd för detta. I första vevan innebär
detta inget mer än att alla metoder i API:et (dvs i SessionFacaderna
och därmed i BusinessDelegaterna) måste ha en inparameter som
representerar användarens identitet.
uPortal har ett inbyggt API för rättigheter som vi ska använda
men jag är ännu inte helt klar över hur det fungerar. Detta
löser vi dock genom att hitta på en egen typ för den extra
inparametern som nämndes ovan. Vi låter den vara ett interface
se.kth.isk.ucalendar.business.security.Authorization. Tills vidare
kan det vara utan metoder och vi kan låta den extra parametern ha värdet
null. Syftet är att den ska kunna innehålla antingen uPortals
klass som hanterar rättigheter eller en egenutvecklad rättighetsklass
om uPortals rättighetshantering inte ska användas. När vi kan
mer om uPortals rättighetssystem kan vi bestämma vilka metoder interfacet
ska ha.
Authentication
All inloggning sker i uPortal och hur den fungerar behöver vi inte
bry oss om.
Hur stoppar vi en attack som sker genom att någon skriver en egen
EJB-klient som försöker koppla upp sig direkt mot vårat EJB-skikt?
Såvitt jag kan se kan vi inte styra över det i och med att uPortal
inte använder J2EE:s deklarativa säkerhetshantering. Vi får
helt enkelt ange att vem som helst får köra alla metoder (method-permission
i deployment descriptorn (DD) sätts till unchecked) och sedan
får vi påpeka risken för den systemansvarige.
Loggning
Vi har inga intrångsförsök att logga eftersom vi inte
hanterar autentitiering. Vi ska logga fel enligt vad som angetts i UCM och
SS.
Transaktioner
Mycket finns att säga om transaktionshantering både vad
gäller EJB:er och databaser. Hur transaktioner sköts har stor
inverkan på prestanda och kan också leda till väldigt svårfixade
buggar. Det här är bara en extremt kort skiss av en metod som
borde funka för oss. Tänk bara aldrig "det där löser
sig i databasen"...
EJB:er
Vi ska använda container managed transactions (CMT), dvs deklarativa.
Alla metoder i SessionFacaderna ska exekveras i egna transaktioner. En ny
transaktion ska påbörjas när metoden startar och slutar
när metoden returnerar. Detta åstadkommer vi genom att i DD sätta
transaktionsattributet till RequieresNew för alla sessionsbönor.
Alla metoder i entitetsbönor ska köras i den transaktion som startades
i den anropande metoden i SessionFacaden. Det innebär att alla metoder
i entitetsbönor ska ha transaktionsattributet Required i DD.
Några ord om JBoss: JBoss gör det enkelt för oss genom
att bara ha en instans av varje entitetsböna laddad åt gången.
Detta innebär att vi inte behöver bekymra oss om transaktionsisolering
(se nedan) eller lås i JBoss. Om vi vi standardjboss.xml ändrar
comitt-option från B till A kommer JBoss
att cacha entiteternas värden och synka med databasen väsentligt
mer sällan. Detta kan ge klart bättre prestanda men funkar bara
om all access till databasen sker via JBoss.
Databasen
Transaktionsisolering
Postgres har default transaktionsisoleringsnivån Read Commited
vilken innebär att en transaktion inte ser uppdateringar gjorda i en
annan transaktion som inte har commitat. Däremot ser en transaktion
alla uppdteringr gjorda av andra commitade transaktioner. Det är alltså
möjligt att två olika select i samma transaktion returnerar såväl
olika rader som olika innehåll i raderna. Normalt är detta inte
något problem men det är bra att vara medveten om det. Read Commited
är snabb och erbjuder oftast tillräckligt skydd.
Uppdateringar gjorda i samma transaktion syns även innan transaktionen
har commitats.
Om en transaktion ska göra en uppdatering och hittar en rad som redan
är uppdaterad av en annan ocommitad transaktion väntar transaktionen
tills den andra transaktionen har avslutats och kollar sedan igen om raden
ska uppdateras.
Lås
Postgres låser normalt inte, varje transaktion får i stället
sin egen bild av databasen. Bilden visar databasen som den såg ut
när transaktionen påbörjades. Detta innebär att vi
aldrig kan veta om läst rad verkligen finns i databasen, den kan ha
blivit borttagen av en annan parallell transaktion. Detta är noramlt
inte heller något problem. Det går att låsa en rad mot
parallella uppdateringar genom att istället för SELECT skriva
SELECT FOR UPDATE.
Några fler designmönster
Dessa var inte med i designexemplen ovan men kan säkert vara användbara
i uCalendar.
EJB
Ett mönster för att generera primära nycklar (kallas Sequence
Blocks)
Det är ofta bäst att ha en primär nyckel som inte betyder
något, dvs att inte ta någon av tabellens "datakolumner" som
primär nyckel. Det här är ett mönster för att generera
unika heltal, vilka är lämpliga att använda som primära
nycklar.
Antag att en godtycklig entitetsböna, ClientEntityBean, behöver
primära nycklar. Vi kan också anta att det finns flera enitetsbönor
som behöver primära nycklar för olika entiteter. Detta kan
lösas med en tjänst PrimaryKeyGenerator, som implementeras
så här mha en sessionsböna (som använder en entitetsböna):
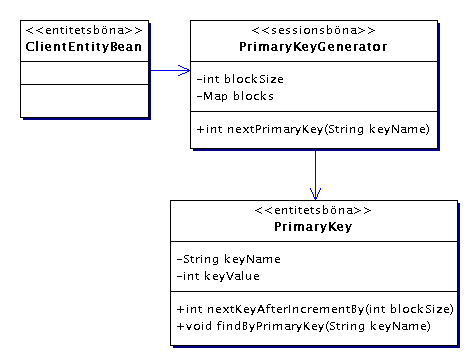
När en ny entitet av ClientEntityBean skapas kommer dess
ejbCreate() att behöva en primär nyckel. Det får
den genom att anropa PrimaryKeyGenerator på detta vis: int myPK
= primaryKeyGenerator.nextPrimaryKey(entityName); PrimaryKeyGenerator
returnerar då en int som är ett större än den
som sist returnerades för samma entitet.
I databasen finns en tabell som innehåller namnet på alla entiteter
och värdetpå senast returnerade primära nyckel förvarje
entitet. För att inte behöva anropa databasen varje gång
en ny primär nyckel ska genereras har PrimaryKeyGenerator själv
en räknare för varje primär nyckel (i blocks) som
ökas med ett för varje nyckel som genereras.
När blockSize nycklar har genererats är det dags att synka med
databsen. Då anropas PrimaryKey.nextKeyAfterIncrementBy()
som ökar raden i databasen där senaste värdetför denna
nyckel finns med blockSize och sedan returnerar det nya värdet.
Detta mönster exekveras snabbast om PrimaryKeyGenerator har
ett lokalt interface (den kommer ändå aldrig att anropas av något
annat än entitetsbönor) samt om vi, till skillnad från vad
som angavs under avsnittet om transkationer, ger nextPrimaryKey()
transaktionsattributet Required och nextKeyAfterIncrementBy()
attributet RequiresNew. Det första för att genereringen
av en primär nyckel hänger ihop med att skapa den nya entiteten.
Det andra för att den nya entiteten kanske skapas i en lång transaktion,
då är det onödigt att låsa tabellen med primära
nycklar under hela den transaktionen. Det skulle fördröja andra
transaktioner som behöver skapa primära nycklar.
ValueListIterator
Detta mönster används när en klient till skiktet business,
tex uCalendar-kanalen, behöver browsa bland en massa rader i databasen.
Antag till exempel att användaren har en jättestor adressbok som
hon/han bläddrar i. Det vore mycket långsamt att skapa en instans
av en entitetsböna Contact för varje rad i adressboken
som ska visas. Vi kan i stället lösa det genom att ha en sessionsböna
som läser direkt ur databasen enligt diagrammet nedan. BusinessDelegaten
(UserDelegate) får då returnera en Iterator
som kan hantera browsandet.
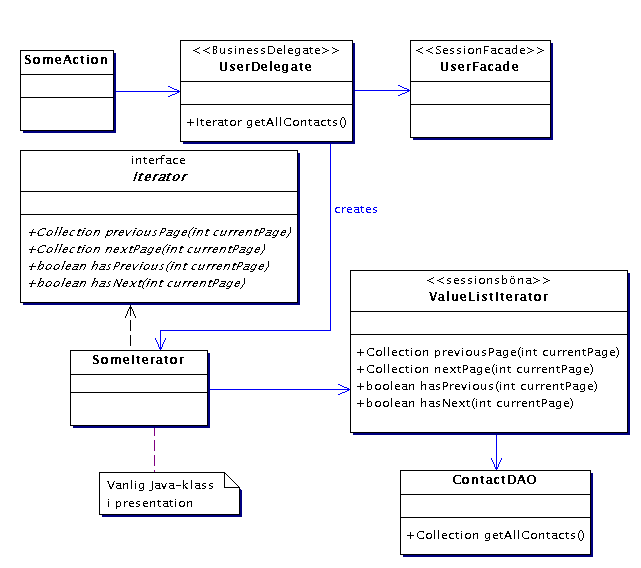
ValueListIterator läser alla rader med kontakter från
databasen mha en DAO och kan sedan cacha alla eller vissa av dessa rader
lokalt. ValueListIterator har metoder typiska för en iterator
för att browsa bland kontakterna. Klassen SomeIterator är
ingen BusinessDelegate men har samma funktion, nämligen att dölja
anropen av EJB:er för resten av presentation. Den har samma metoder
som sin sessionsböna. Användaren kan nu scrolla i sin adressbok
utan att det behöver göras ideliga databasanrop. När användaren
bestämmer sig för att göra en ändring i adressboken används
inte längre ValueListIterator, då är det i stället
dags att gå på entitetsbönan Contact.
Antingen använder vi samma ValueListIterator oavsett vad som ska browsas,
då måste den ta emot en parameter som talar om vad vi vill browsa,
eller skriver vi en unik klass för allt som ska kunna browsas, i så
fall vora det lämpligare att kalla den till exempel ContactIterator.
Om sessionsbönan ska hålla reda på cursorn (alltså
vilken som är aktuell rad) måste den vara tillståndsfull.
Ett alternativ är att sessionsbönan är tillståndslös
och att SomeIterator håller reda på cursorn och skickar
med den i varje metodanrop av sessionsbönan (så ser det ut i
diagrammet).