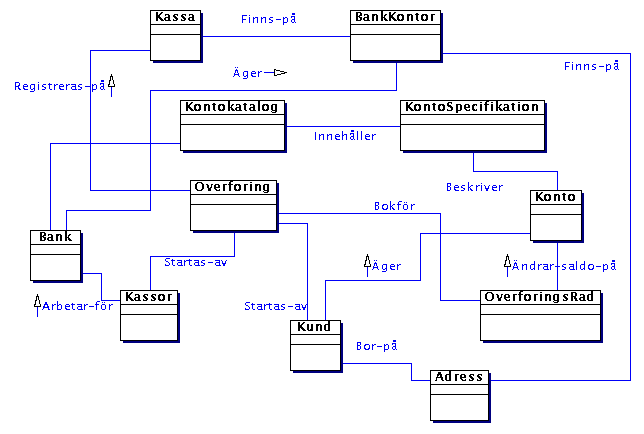
| Kategori |
Banksystem |
Flygbokningssystem |
| Fysiska objekt som går att ta på |
Blankett Pengar |
Flygplan |
| Specifikationer och Beskrivningar |
KontoNummer KontorsID (vid vilket kontor kunden är) |
FlightBeskrivning |
| Platser |
Bankkontor KundAdress |
Flygplats |
| Transaktioner |
Överföring |
Reservation |
| Rader i transaktioner |
ÖverföringsRad (datum, kontonr, belopp osv) |
|
| Roller |
Kund, Kassör |
Pilot |
| Behållare för saker |
Flygplan |
|
| Saker i behållare |
Passagerare |
|
| Externa system |
||
| Abstrakta substantiv |
Flygskräck, Rökare |
|
| Organisationer |
Bank |
Flygbolag |
| Händelser |
Avbrott (i kommunikationen mellan terminalen och systemet) |
Landning Krasch Flight |
| Processer |
Överföring |
Bokning |
| Regler |
Uttagsavgifter Räntor |
Avbokningsvillkor |
| Kataloger |
Kontokatalog (innehåller specifikationer
för olika sorts konton) |
Tidtabell |
| Journaler, loggar |
Kvitto |
|
| Finansiella värden och tjänster |
Belopp |
Tillgodohavande |
| Manualer, böcker och andra dokument |
RabattLista |
| Kategori |
Banksystem |
| A är en fysisk del av B |
Kassa - Kassaskrin |
| A är en logisk del av B |
ÖverföringsRad - Överföring |
| A finns fysiskt inuti B |
Kassa - BankKontor |
| A finns logiskt inuti B |
KontoKatalog - KontoSpecifikation |
| A är en beskrivning av B |
KontoSpecifikation - Konto |
| A är en rad i en transaktion eller en rapport av typ B |
ÖverföringsRad - Överföring |
| A loggas i B |
Överföring - Kvitto |
| A är medlem i B |
Kassör - Bank |
| A är organisatoriskt en avdelning i B |
BankKontor - Bank |
| A använder B |
Kassör - Kassa Kund - Blankett |
| A kommunicerar med B |
Kund - Kassör |
| A är relaterad till en transaktion av typ B |
Kund - Överföring Kassör - Överföring |
| A och B är transaktioner med inbördes relation |
|
| A är i positionen efter B i någon form av datasamling |
ÖverföringsRad - ÖverföringsRad |
| A ägs av B |
Bank - BankKontor Kund - Konto |