Designövning: design av ett ramverk
Boken som refereras nedan (Larman) är Larman: Applying UML and
Patterns (Prentice-Hall 2002) ISBN:
0-13-092569-1
Syftet med övningen
I den här övningen
ska vi designa ett ramverk för persistenta objekt. Ett
sådant
ramverk innehåller många komplexa problem, dessutom finns
det redan flera färdiga
ramverk för persistens. Syftet med övningen är
altså
inte att skapa ett färdigt komplett ramverk utan att öva
på
design, att ge en förståelse för hur ett ramverk
fungerar
samt att vara en introduktion till OR-mappning.
Några designmönster som används i lösningen
Proxy (33.3 och 34.18)
Ursprung
GoF
Problem
Vi kan eller vill inte ge publik access till ett visst objekt.
Lösning
Skriv en ny klass, en proxy, som har samma publika gränssnitt som
objektet och håller en referens till det. Vi kan nu lämna ut
referensen till proxyn och låta den sköta om hanteringen av
access till det känsliga objektet.
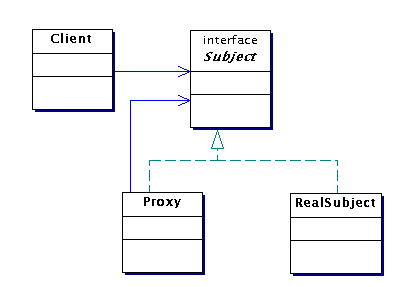
Kommentarer om implementation av mönstret
- En proxy kontrollerar accessen till ett visst objekt och har
därför möjlighet att tillföra någon
funktionalitet utöver
en vanlig referens av det kontrollerade objektet. Nedan kommer
några
olika exempel på vad en proxy kan göra. I samtliga fall
är Client fullkomligt oberoende av vad proxyn egentligen
har för sig.
- Remote Proxy
Om RealSubject finns i en annan process används en
remote proxy för att dölja hanteringen av
nätverksanropen.
- Redirection Proxy (Failover Proxy)
Provar först att anropa ett visst RealSubject. Om det av
någon anledning inte kan utföra operationen anropas ett
annat RealSubject.
- Virtual Proxy
Om det krävs mycket resurser för att skapa ett visst objekt
och/eller det inte är säkert att det kommer att behövas
kan vi i stället skapa en virtual proxy till objektet. Den skapar
inte objektet
förrän första gången det används.
- Copy-On-Write
Om ett komplext objekt ska kopieras är ett alternativ att
låta bli att kopiera och i stället lämna ut en proxy
till objektet. Kopieringen sker först när det sker en
skrivning.
- Protection Proxy
Utför någon form av säkerhetskontroll.
Exempel
- Figur 33.13 på sid 522 i Larman (redirection proxy)
- Figur 34.16 på sid 560 i Larman (virtual proxy)
Mönstrets starka sidor
Vi har tidigare sett fördelarna med att göra ett objekt av
en egenskap (Observer), algoritm (Strategy) och operation (Command).
Proxy är ett sätt att göra ett objekt av en referens.
Det innebär att vi kan lägga till godtycklig funktionalitet
till själva referensen.
Abstract Factory (33.6)
Ursprung
GoF
Problem
Hur ska vi skapa familjer av relaterade objekt utan att behöva
känna till klassnamnen?
Lösning
Skapa ett interface (AbstractFactory). Skapa en konkret
implementation (ConcreteFactory) av det för varje familj
av objekt.
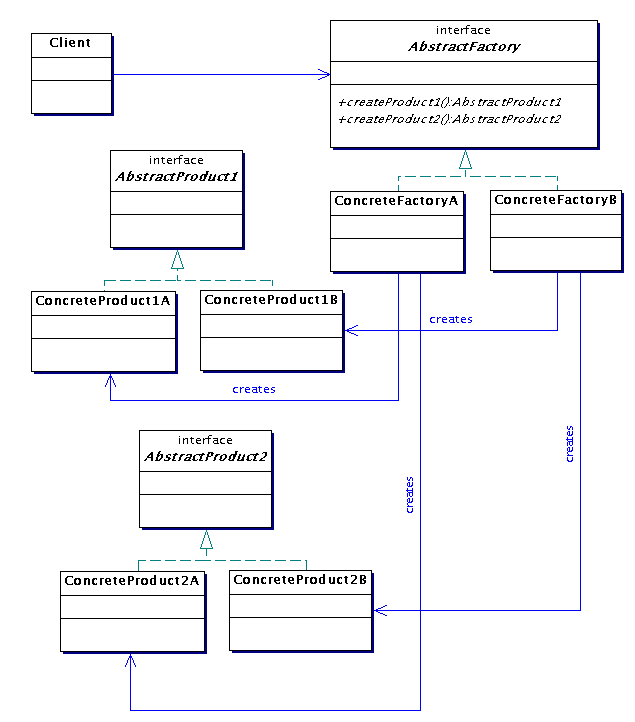
Exempel
Figur 33.15 på sid 526 i Larman.
Kommentarer om implementation av mönstret
- De olika ConcreteFactory är starka kandidater
för att vara singleton.
- Vi kan skapa ett fristående ConcreteFactory (se avsnittet Några
designmönster i GoF-katalogen) som skapar instanserna av de
olika ConcreteFactory. Om det läser från en
miljövariabel eller fil vilken familj av objekt som ska skapas kan
vi ändra det utan att behöva ändra i koden. En vanlig
lösning är att göra om AbstractFactory
från ett interface till en abstrakt klass och låta metoden
som skapar instanser av ConcreteFactory vara en statisk metod
i den. Detta illustreras av den översta koden på sid 527 i
Larman.
- Med lösningen ovan är det nödvändigt att
utöka det publika gränssnittet i AbstractFactory
varje gång en ny typ av objekt ska läggas till i familjerna.
Detta kan undvikas om vi ändrar AbstractFactory så
att den bara har en
metod som tar en parameter som anger typen av det objekt som ska skapas
(parametern är lämpligtvis klassnamnet). Problemet med den
lösningen
är att metoden måste returnera ett objekt av typen Object
som sedan måste castas. Detta är en klassisk och ofta
förekommande motsättning mellan flexibilitet och
typsäkerhet.
Mönstrets starka sidor
- Client blir oberoende av de olika ConcreteProduct.
- Det blir lätt att byta mellan olika produktfamiljer.
- Bidrar till att produkter i olika familjer får samma
funktionalitet eftersom de måste implementera samma interface.
Mönstrets svaga sidor
Det är svårt att lägga till nya typer av produkter
eftersom gränssnittet för alla factory-klasser då
måste utökas.
Besläktade mönster
- Det är lämpligt att implementera factory-klasser som
singleton.
Template (mall) method (34.11 - 34.12)
Ursprung
GoF
Problem
Flera metoder/algoritmer innehåller stora mängder gemensam
kod men varierar till viss del. Hur ska vi undvika att duplicera den
gemensamma koden?
Lösning
Placera den gemensamma koden i en metod (template method) i en
superklass och placera den varierande koden i abstrakta metoder i
superklassen. De
olika variationerna blir då implementationer av de abstrakta
metoderna
i subklasser.
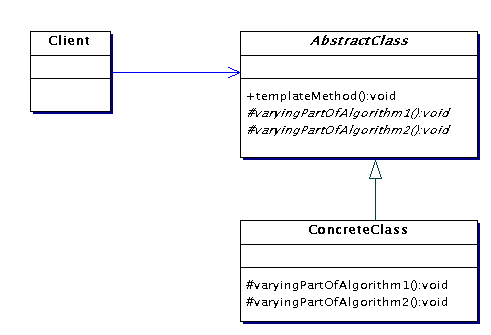
Exempel
Figur 34.7 på sid 547 i Larman.
Kommentarer om implementation av mönstret
- Det är lämpligt att de abstrakta metoderna har protected/protected
internal åtkomst eftersom de inte ska kunna anropas av Client.
- Detta är ett exempel på klasser som är avsedda
att ärvas, se restriktioner för dessa i avsnittet
Arv.
- Det finns en mer eller mindre vedertagen namnkonvention som
är att ge den abstrakta metoden samma namn som templateMethod
men
med prefixet do.
Mönstrets starka sidor
Ett bra sätt att undvika duplicerad kod. Används ofta i
ramverk.
Besläktade mönster
I Strategy används delegering för att byta en hel algoritm,
här används arv för att byta delar av en algoritm.
State (34.16)
Använd State när du frestas skriva if-satser för att
välja beteende beroende på ett objekts tillstånd.
Ursprung
GoF
Problem
Metoder i ett objekt innehåller en massa if-satser för att
välja beteende utifrån objektets tillstånd.
Lösning
Skapa ett interface med de tillståndsberoende metoderna och en
implementerande klass för varje tillstånd. Flytta all
tillståndsberoende kod till dessa klasser. Om objektet alltid har
en klass som symboliserar dess aktuella tillstånd kan det
delegera de tillståndsberoende operationerna till denna klass.
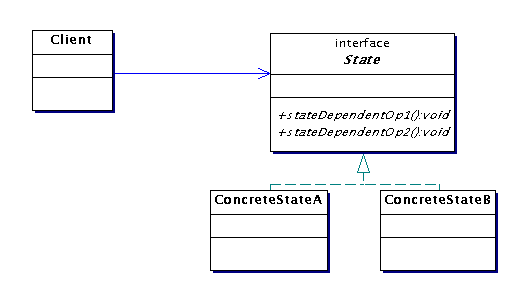
Exempel
Figur 34.12 på sid 554 och figur 34.14 på sid 557 i Larman.
Kommentarer om implementation av mönstret
- ConcreteState kan vara tillståndslösa om de
antingen får en referens till Client eller tar allt
tillstånd som inparametrar i sina metoder.
- Om ConcreteState är tillståndslösa kan
de delas av alla klienter. De kan då vara singletons.
- ConcreteState kan hanteras av ett factory.
- Vem ska hantera tillståndsbyte? Den rättframmaste
lösningen är nog att låta Client göra
det men det ger gärna komplex och oflexibel kod. Ett alternativ
är att ConcreteState hanterar tillståndsbyte. Om
så är fallet kan det vara
lämpligt att låta Client implementera att
interface
med en metod setState() så att ConcreteState
inte
blir beroende av klassen Client. Även denna lösning
har en nackdel, nämligen att varje ConcreteState
måste
känna till minst en annan ConcreteState.
Mönstrets starka sidor
- Enklare kod och högre sammanhållning.
- Clients tillstånd blir tydligare än om det
bara är summan av dess instanvariabler.
Besläktade mönster
Representing Objects as Tables (34.6)
Ursprung
(Brown and Whitenack: Crossing Chasms. Pattern Languages of Program
Design, vol 2 (Addison-Wesley 1996)
Problem
Hur sker omvandlingen mellan en objektorienterad modell och en
relationsdatabas? Detta problem måste lösas i alla
objektorienterade program som använder en relationsdatabas och
är alltså väldigt vanligt. Det är däremot
inte helt lätt eftersom de två modellerna är så
olika. Målet med ett objektorienterat program är att det ska
vara flexibelt (och lättförstått) medans målet
med en relationsdatabas är att säkerställa
dataintegritet vid uppdatering genom att undvika duplicering av data.
Lösning
Låt varje klass motsvaras av en tabell i databasen och låt
varje instans av klassen vara en rad i tabellen, se figur 34.1 på
sid 541 i Larman.
Mönstrets starka sidor
Väldigt lätt att tillämpa.
Mönstrets svaga sidor
Mönstret resulterar i ett försök att kopiera den
objektorienterade modellen till databasen vilket gör att styrkan
med att ha två olika modeller (relationer och objektorientering)
inte utnyttjas. Det är nästan alltid bättre att utveckla
databasen och den objektorienterade modellen oberoende av varandra och
sedan skriva ett lager som sköter mappningen mellan dem. Detta
mönster är bra som utgångspunkt för OR-mappning
men att tillämpa det strikt fungerar bara på så
extremt enkla modeller att det knappast är tillämpligt.
Object Identifier, OID (34.8)
Ursprung
(Brown and Whitenack: Crossing Chasms. Pattern Languages of Program
Design, vol 2 (Addison-Wesley 1996)
Problem
Hur ska vi veta exakt vilket objekt ett visst data i databasen
representerar? Hur ska vi kunna behålla identiteten på ett
viss entitet (se ordlistan) om den ibland är i objektorienterad
form och ibland i databasen?
Lösning
Ge varje entitet ett unikt ID. Ett visst ID symboliserar då
entiteten både i dess objektorienterade form och i databasen.
Kommentarer om implementation av mönstret
- I databasen sparas ID:t som primär nyckel och i programmet
sparas det lämpligtvis i en egen klass. Objektet som representerar
entiteten har då en referens till OID-klassen. Se figur 34.3
på sid 542 i Larman.
- Mönstret säger ingenting om hur ett OID genereras. Det
finns många olika mönster som löser detta men det
ligger utanför den här kursen.
Database Mapper, även kallad Home Object (34.10)
Ursprung
Fowler: Draft patterns on object-relational persistence services
(Enligt Larman finns det på www.martinfowler.com men jag hittar
det inte där)
Problem
Vem är ansvarig för att spara och läsa ett objekt
från databasen?
Lösning
Detta mönster föreslår indirect mapping, dvs
att skapa en ny klass (en Pure Fabrication) för detta
ändamål. Det blir en mapper-klass för varje kombination
av persistent objekt och sätt att spara det, se figur 34.5
på sid 545 i Larman.
Mönstrets starka sidor
Koden som sparar och läser objekt från databasen blir helt
oberoende av vilka objekt som hanteras och hur de sparas.
Mönstrets svaga sidor
Det är nödvändigt att skriva en ny mapper för
varje kombination av persistent objekt och sätt att spara det.
Detta
kan undvikas genom att använda metadatabaserade mappers. En
sådan hanterar mappningen genom att läsa metadata om
mappningen (till exempel "tabell X mappas till object Y"). Detta
fungerar i språk som har reflexion (tex Java och C#), dvs
där det finns möjlighet att programmatiskt ta reda på
till exempel vilka fält och metoder en klass har.
Att skriva en metadatabaserad mapper är väsentligt
krångligare än att skriva en som bara hanterar en viss
förutbestämd kombination av objekt och lagringsmedia, men
å andra sidan räcker det med en enda mapperklass.
Besläktade mönster
- En mapper ger Protected Variations med avseende på
mappningen.
- En mapper är en Pure Fabrication
- En mapper kallas även för Home Object.
Cache Management (34.14)
Ursprung
(Brown and Whitenack: Crossing Chasms. Pattern Languages of Program
Design, vol 2 (Addison-Wesley 1996)
Problem
Att läsa och skriva i en databas tar relativt lång tid.
Lösning
Skapa en cache för persistenta objekt. När ett objekt ska
läsas från databasen letar vi först efter det i cachen
och anropar bara databasen om det inte finns där. När ett
objekt
ska sparas behöver vi inte alltid skriva det till databasen utan
kan
ibland spara det i cachen.
Kommentarer om implementation av mönstret
Om vi använder direkt mappning (se Database Mapper) och inte
har metadatabaserade mapperklasser (se Database Mapping) kan varje
mapperklass hantera en cache av sin typ av objekt. Den kan då
implementeras
som en hashtabell där nycklarna är objektens OID (se Object
Identifier).
Mönstrets starka sidor
Väsentligt förbättrad prestanda.
Mönstrets svaga sidor
Att hantera cacher är mycket komplicerat och ligger utanför
den här kursen. Exempel på problem är om databasen
används även av andra program eller om flera olika
trådar hanterar samma objekt.
Kravspec
Instanserna av ProductSpecification (se till exempel figur
17.8
på sid 258 i Larman) i NextGen POS måste vara persistenta.
För
detta ändamål ska ett egenutvecklat ramverk för
persistens
användas. Ramverket ska var generellt så att det kan
användas
även för andra typer av persistenta objekt. Det ska
också
vara oberoende av vilken produkt som används för att lagra
objekten
(tex olika typer av relationsdatabaser, objektorienterade databaser
eller
XML-filer).
Lösning: Ramverket
Det hade varit tjusigt om kapitel 34 i Larman följt den modell
för
mjukvaruutveckling som resten av boken beskriver. Det vill säga
ett
itererande över kravspec (i form av tex use case och supplementary
specification),
domänmodell samt design (med hjälp av de grundläggande
mönstren
som tex Information Expert). Så är tyvärr inte fallet
utan
i stället är kapitlet en beskrivning av en färdig design.
För att öka förståelsen något och inför
någon
form av process kan vi betrakta det som att vi löser
nedanstående
problem i angiven ordning.
- Det första steget blir att bestämma hur ramverket ska
accessas.
Larman har beslutat sig för att lösa det med en Facade.
- Därefter är det dags att klura på exakt hur
objekt
ska läsas från och skrivas till lagringsmediat.
- Sedan tittar vi litet på ramverkets trådsäkerhet.
- Efter det funderar vi på om vi ska minska antalet
läsningar/skrivningar
genom att objekt cachas av ramverket.
- Nästa steg är hur och när uppdateringar av
instansierade
objekt ska skrivas i databasen.
- Sluligen funderar vi på OR-mappning.
En identitet för ett objekt som är gemensam för
ramverket
(programmet) och alla olika lagringsmedia.
Steg ett är att designa ramverkets facad. Den måste ha
metoder
för att instansiera ett objekt (get(...)) och för
att
spara det (put(...)). För att detta ska fungera
måste
objekten ha en identitet som fungerar både när de är
instansierade
i programmet och när de är sparade i lagringsmediat. Detta
löses
med hjälp av mönstret Object Identifier.
En Facade för att accessa ramverket
Nu kan vi designa facaden. Den heter PersistenceFacade och
finns
i figur 34.4 på sid 543 i Larman.
Home Object (Database Mapper) för att instansiera persistenta
objekt
Nu är vi framme vid steg två, exakt hur objekt ska
läsas
och skrivas. Facaden ska inte göra detta själv (eftersom
själva
syftet med en facade är att den ska delegera arbetet).
Operationerna
get() och put() ska i stället skötas
enligt mönstret
Database Mapper. Detta ger oss designen i figur
34.5 på sid 545 i Larman. PersistenceFacade har en
hastabell
med alla Mapper. Nycklar i den är klasser som kan
instansieras
och värden är Mapper-implementationer som kan
instansiera
objekt av klassen i nyckeln.
Det visar sig att en del kod kommer att dyka upp i alla Mapper
vi
skriver, nämligen den som finns i pseudokoden på sid 546 i
Larman.
Eftersom duplicerad kod av naturen är något ont vill vi
undvika
detta. Det kan vi göra med hjälp av mönstret Template
method, vilket ger designen i figur 34.8
på sid 548 i Larman.
Vi kan använda Template method en gång till eftersom
ytterligare
en del kod blir gemensam för alla Mapper som
använder
samma lagringsmedia. Figur 34.9 på sid 549 i Larman visar en Mapper-hierarki
för relationsdatabaser.
Notera hur vi genom att använda Template method får den
typiska
egenskapen för ett ramverk: Att klasserna som använder
ramverket
innehåller metoder som ansvarar för en viss operation, men
ramverket
är ansvarigt för att de anropas vid rätt tillfälle.
Detta
framgår av figur 34.10 på sid 550 i Larman.
Ska ramverket vara trådsäkert?
Det är nödvändigt att vi bestämmer och dokumenterar
i
vilken utsträckning ramverket är trådsäkert. I det
här
fallet bestämmer vi att ramverket ska vara trådsäkert
vilket
gör att till exempel metoden get() i AbstractPersistenceMapper
är en kritisk sektion. Om flera trådar kom in i den
samtidigt
skulle flera objekt med samma OID kunna instansieras. Detta illustreras
av
figur 34.11 på sid 551 i Larman.
Concrete factory för synlighet till Database Mappers
Koden på sid 552 i Larman visar denna lösning. Ett
alternativ
till att lämna ut en hashtabell med alla Mapper är
att
MapperFactory har en enda metod
Mapper getMapper(String mapperType)
där mapperType är en nyckel med vars hjälp MapperFactory
kan läsa klassnamnet för önskad Mapper.
Data Access Object (facader för lagringsmediet)
Nedanstående resonemang rör relationsdatabaser och SQL men
exakt
samma sak gäller för access av alla typer av externa system.
Att sprida ut SQL-satser lite överallt är ett
välkänt
antimönster som kallas SQL Everywhere. För att
undvika detta
samlar vi alla SQL-satser i objekt som är till enbart för
access
av databasen. Sådana objekt kallas ibland Data Access Object
(DAO).
Detta illustreras av koden på sid 553 i Larman. Metodsignaturerna
i
DAO:erna ska vara skrivna för att passa de klasser som anropar
dem,
inte för att passa databasen. Detta mönster (DAO) ger
följande
vinster:
- Vi undviker duplicerad SQL-kod.
- Det blir lättare att dela ansvarsområden vilket
är
bra eftersom det ofta inte är samma person som hanterar SQL och
den
objektorienterade programmeringen.
- Om vi ska byta databas och den nya databasen har en annan syntax
är
det lätt att byta SQL-satserna, det är bara att skriva (och
instansiera)
en ny DAO.
- Det blir lätt att införa någon ytterliga
hantering
av SQL-satserna, till exempel att läsa dem från en fil eller
generera
dem dynamiskt.
Cache-hantering
Eftersom det tar lång tid att accessa till exempel en databas kan
vi
väsentligt förbättra prestanda genom att spara
instansierade
objekt i en cache. Detta beskrivs ytligt av mönstret Cache
management som dock inte säger hur och
när cachen ska uppdateras.
Transaktionshantering
Detta är ett stort och komplext område som inte ingår
i
kursen. Extremt kortfattat är en transaktion en samling
operationer
på till exempel en databas som utförs atomärt (alla
eller
ingen av dem utförs). Transaktionen har tre operationer:
- begin Transaktionen påbörjas. Resultatet av
operationer
på databasen som följer lagras bara temporärt.
- commit Vid commit uppdateras databasen så att alla
läsningar/skrivningar/uppdateringar
osv som utförts efter begin lagras permanent.
- rollback Alla förändringar på databasen
efter begin tas bort. Databasen är oförändrad
och de
temporärt lagrade uppdateringarna kastas.
Detta är ett utmärkt tillfälle att använda ett
tillståndsdiagram.
Figur 34.12 på sid 554 i Larman visar vilka olika tillstånd
ett
persistent objekt kan vara i med avseende på
transaktionshanteringen.
Var finns transaktionens metoder? De ärvs!
Var ska vi placera metoderna begin(), commit() och rollback()?
Tillståndsdiagrammet i figur 34.12 innehåller dessutom
ytterligare
operationer, tex save() och delete() som ska finnas
i alla
persistenta objekt. save() betyder att uppdateringar av
objektets
tillstånd ska skrivas i databasen vid commit och delete()
betyder att objektet ska tas bort ur databasen vid commit.
I figur 34.13 på sid 555 föreslår Larman att alla
objekt
ska ärva av en klass i ramverket, PersistentObject, som
innehåller
dessa metoder. Detta är, även enligt Larman själv, en
enkel
men inte helt lyckad lösning. Problemet med den är att vi
blandar
in databasrelaterad kod i alla persistenta objekt vilket ger mycket
hög
koppling. Det ger även låg sammanhållning (low
cohesion)
eftersom alla som skriver objekt som ska kunna sparas persistent
måste
vara medvetna om den databasspecifika koden. En alternativ lösning
presenteras
längre ned på sidan.
Hur hanteras transaktionens olika tillstånd?
Rutorna med kod på sid 555 i Larman visar att ett
försök
att koda metoderna i PersistentObject ger upphov till
duplicerad
kod i form av stora if-krattor. Detta kan undvikas med hjälp av
mönstret
State enligt figur 34.14 på sid 557 i Larman.
Hur sker den temporära lagringen av alla uppdateringar i en
transaktion?
Nästa problem med transaktionshanteringen är att
databasoperationer
inte får utföras bums utan måste sparas i någon
sorts
lista tills commit utförs. Antag till exempel att vi i en viss
transaktion
uppdaterar ett objekt (save()) och tar bort ett annat (delete()).
Någonstans måste det finnas en referens till dessa
två
objekt och information om att de ingår i samma transaktion. Detta
är
ett utmärkt tillfälle att använda mönstret Command
som gör ett objekt av en operation
och därmed låter oss placera den i en lista. Denna
lösning
framgår av figur 34.15 på sid 559 i Larman. Larman har
där
infört en ny klass, Transaction. Dess uppgift är
just
att gruppera alla operationer och objekt som ingår i samma
transaktion.
Det framgår inte av figuren vem som ska anropa Transaction
men det är PersistentObject.
Var finns transaktionens metoder (alternativ lösning)? I ett
automatgenererat
objekt!
I stället för att placera dessa i en klass som ärvs (PersistentObject)
kan vi lösa det genom att PersistenceFacade inte
lämnar
ut en referens till det egentliga persistenta objektet utan till en
Proxy till det. Proxyn ska innehålla metoder
med samma signatur som metoderna i det persistenta objektet. Dessa ska
då,
förutom ett anropa motsvarande metod i det persistenta objektet
även
anropa Transaction. Dessutom ska proxyn innehålla de
metoder
(commit() osv) som i Larmans lösning finns i PersistentObject.
Det jobbiga med denna lösning är att proxyns kod beror av det
persistenta
objektets publika gränssnitt. Det innebär att det måste
automatgenereras
en proxy för varje typ av persistent objekt. I Java finns ett API
(dynamic
proxy) för automatgenerering av proxys. Säkerligen finns
något
liknande i C#.
Uppgift
- Försök rita ett interaktionsdiagram som visar
samarbetet
mellan PersistentObject, Transaction, State- och
Command-klasserna
samt det persistenta objektet.
- Samma uppgift när en proxy används i stället
för PersistentObject.
Hur objekt kan mappas till tabeller i en relationsdatabas
Mönstret Representing Objects as Tables
ger ett lättanvänt men väldigt grovt förslag
på
hur data kan lagras. Mönstret Representing Object
Relationsships
as Tables (avsnitt 34.19 i Larman, tas inte upp här) ger ett
ungefär
lika enkelt och grovt förslag på hur relationer mellan
objekt
lagras.
Sanningen är att en mappning mellan dessa bägge världar
är
ett klart mer komplext problem, eftersom de har utvecklats under helt
olika
förutsättningar, i olika riktningar, för att lösa
skilda
slag av problematik. Det enda som praktiskt fungerar lära vara att
databasen
och programmet utvecklas oberoende av varandra av experter på
respektive
område och att man sedan skriver ett extra lager som sköter
mappningen mellan dem. Denna mappning hamnar i vår lösning i
DAO:erna. Angående dessa är det lämpligt att deras
publika
gränssnitt skrivs av de som utvecklar programmet medans deras
implementationer
(åtminstone SQL-satserna) skrivs av de som utvecklat databasen.
Olösta problem
Detta är långt ifrån en komplett lösning. Exempel
på
vad som fattas är
- Endast get() har implementerats i PersistenceFacde
och Mapper-klasserna.
- Vi har bara ett embryo till transaktionshantering.
- Det finns varken felhantering eller säkerhetshantering.
- Vi har bara tagit en väldigt ytlig titt på
trådsäkerhet.