Introduktion till arkitektur
Boken som refereras nedan (Larman) är Larman: Applying UML and
Patterns (Prentice-Hall 2002) ISBN:
0-13-092569-1
Introduktion
Arkitekturen är systemets "skelett", hur det
ser ut i stora drag. Arkitekturen talar om vilka problem
som löses och var de löses men inte hur (det
hör till design). Jämför arkitektens roll vid ett
husbygge: Antag att det behövs en hiss, arkitekten ritar då
ett hisschakt, designern ritar en hiss och en hissmotor och
konstruktören monterar in hissen. Ytterligare ett annat sätt
att förklara
begreppet arkitektur är att se det som en vy av systemet
från
1000 meters höjd, bara de stora dragen syns. Arkitekturen ska
garantera att de ickefunktionella kraven kan lösas.
Liksom analys och design består även arkitekturen både
av
en statisk och en dynamisk modell. I designen är den statiska
modellen
klassdiagram över mjukvaruklasser, i arkitekturen är det
diagram
över subsystem och andra viktiga delar. Den dynamiska modellen i
designen
är interaktionsdiagram som visar hur mjukvaruklasserna samarbetar,
i
arkitekturen visar de hur subsystem samarbetar.
Arkiekturen består också av en motivering av varför en
viss
lösning är vald.
Arbetet med arkitekturen
Arbetet med arkitekturen inkluderar dels att hitta kraven på den,
främst
ickefunktionella men även funktionella krav (architectural
investigation)
dels att ta fram hård- och mjukvara som löser dem (architectural
design).
Ickefunktionella krav
Alla krav på ett program som inte har att
göra med vad programmet ska göra utan hur
det ska fungera. Typiska exempel på ickefunktionella krav
är krav på prestanda, tillgänglighet,
tillförlitlighet, säkerhet, hur lättunderhållet
programmet ska vara,
hur lättanvänt det ska vara, hur lätt det ska gå
att administrera osv. Det är mycket viktigt att beakta de
ickefunktionella kraven innan programmet börjar
utvecklas. Det är också viktigt att uttrycka de
ickefunktionella kraven så att det går att verifera om de
uppfylls.
Arkitekturen måste garantera att de ickefunktionella kraven kan
lösas. Därför är det nödvändigt att
klargöra vilka ickefunktionella krav som ställs på
systemet. Det finns många olika definitioner av ickefunktionella
krav men de vanligaste kraven att beakta är dessa:
Tillgänglighet (availability) och pålitlighet (reliability)
Tillgänlighet används för att försäkra sig
om att tillräckligt många användare kommer åt
systemet tillräckligt ofta. Det kan till exempel anges som
"igång 98% av tiden" eller "otillgängligt max 4 minuter
under en vecka". Pålitlighet är ett mått på i
vilken utsträckning en användare kan förvänta sig
att systemet ska ge ett korrekt resultat. Det kan till exempel vara
"max en av 1000 sessioner misslyckas". Observera att det handlar om
misslyckanden på grund av att systemet är (blir)
otillgängligt, inte på grund av att detger fel resultat.
Lättunderhållet (manageability)
Anger hur komplext systemadministratörens arbete får vara.
Ett exempel är "högst 2 arbetstimmar per månad för
att installera uppgraderingar".
Konfigurerbart (configurability, flexibility)
Utökningar och förändringar som inte rör de
funktionella kraven, tex att byta språk i
användargränssnittet eller att lägga till en ny typ av
klient. Det finns inget tydligt sätt att mäta detta, det
bästa är att försöka uppskatta arbetstid, kostnad
och sannolikhet för förändringar.
Lättutökat (adaptability, extensibility)
Utökningar och förändringar som rör de funktionella
kraven, tex att lägga till nya typer av rabatter i NextGen POS. Se
konfigurerbarhet för möjligheter att mäta detta.
För
övrigt handlar i stort sett hela kursen om att möta krav
på
detta område.
Prestanda
Till exempel "första synliga tecken på svar inom 3 sekunder
i 95% av fallen mätt från yttre brandväggen". Det som
framför allt tar tid är anrop till andra processer, speciellt
att koppla upp sådana förbindelser.
Kapacitet
Ett mått på hur mycket som kan utförs samtidigt (concurrent),
alltså inte parallellt. Ett krav kan vara "100 samtidiga
transaktioner".
Skalbart (scalability)
Egenskapen att systemet kan uppfylla samma ickefunktionella krav
när lasten ökar om ytterligare hårdvara tillförs.
Vertikal skalning är att tillföra ytterligare hårdvara
(tex processorer och minne) till befintliga datorer. Horisontell
skalning är att tillföra fler burkar. Om skalbarheten ska
mätas måste vi definera vilka ickefunktionella krav som ska
skala och i vilken omfattning, till exempel "bibehållen prestanda
vid 90% lastökning om antalet servrar dubbleras".
Användbarhet (usability)
Till exempel "skärmbilden ska synas på en meters håll".
Säkerhet
Säkerhet är ett stort och viktigt område som absolut
måste övervägas noga på ett tidigt skede. Att
försöka lägga till säkerhetshantering i ett
befintligt program är en mycket otrevlig uppgift. Ett mätbart
krav på säkerheten kan vara "det ska ta minst 30 minuter med
bäst kända teknik för attacker att förändra en
användares saldo" eller "tre misslyckade
inloggningsförsök i följd ska loggas". Exempel på
olika säkerhetsaspekter är:
Styrka identiteten, autentisering (authentication)
Hur ska användarens identitet styrkas? Med någon form av
certifkat? Med inloggning? Var finns i så fall lösenord
sparade?
Rättigheter (authorization)
Har olika användare olika rättigheter? Hur hanteras det?
Non-repudiation
Egenskapen att det inte går att förneka något som
gjorts, till exempel att ett visst meddelande skickats. Deta
åstadkoms till exempel genom att använda någon form av
digital signatur.
Integritet (integrity)
Data kan inte modifieras på något otillåtet
sätt. Till exempel kanske vi måste vara säkra på
att data som skickas över ett nätverk kommer fram
opåverkat.
Loggning (auditability)
Vad ska loggas och vart? Hur ska det förhindras att loggen
påverkas av en inkräktare?
Paketering
Hur produkten ska levereras.
Standarder
Krav på standarder som måste följas.
Krav på att använda viss hård- och mjukvara
Dess krav kan komma sig till exempel av att systemet ska integreras med
något befintligt eller av kostnadsskäl (exempelvis "endast
open source-produkter får användas").
Architectural investigation
Architectural investigation är en del av arbetet med att ta fram
kravspecen och ingår alltså inte i kursen.
Kom ihåg att inte skriva en orealistisk önskelista, det
är ingen idé att ställa onödigt stora
ickefunktionella krav på produkten. Kom också ihåg
att det måste gå att verifera att kraven uppfylls.
Vidare kan det vara lämpligt att gradera kraven efter hur viktigt
det är att de uppfylls och hur svårt det är att
uppfylla dem. Figur 32.2 på sid 492 i
Larman visar ett exempel på hur ickefunktionella krav kan
formaliseras.
Architectural design
Allt vi hittils gått igenom i kursen om objektorienterad design
har varit tämligen plattformsoberoende. Vi gör på samma
sätt oavsett vilket språk vi använder och vilket
operativsystem programmet körs på. Arbetet med att utforma
en arkitektur som tillgodoser de ickefunktionella kraven är
tvärtom i högsta grad plattformsberoende. Det beror på
att det är arkitekturen som sätter ramarna
för designarbetet. Om det till exempel finns ett krav på
loggning
väljer vi förmodligen att använda ett färdigt
loggnings-API,
vi kommer då säkert att välja ett annat API om vi
använder
C# än om vi använder Java.
Det kan vara lämpligt att spara information om arkitekturella
beslut, alternativ till dem och vilka faktorer som styrde beslutet. Det
finns annars en risk att andra inte förstår beslutet eller
att arkitekten
glömmer varför beslutet togs och måste göra om
arbetet.
På sid 494, 495 och 497 i Larman finns exempel på hur
sådana
anteckningar kan se ut.
Vad är resultatet av arbetet med arkitekturen?
Arkitekturen täcker flera olika områden. En komplett
beskrivning av den måste innehålla:
- En logisk vy som visar uppdelningen av mjukvaran i lager
och komponenter. Däremot är själva mjukvaran inte en del
av
arkitekturen. Arkitekturen ska visa att ett visst problem kan
lösas
och var det löses. Hur det löses är
däremot
en del av designen.
- En deployment-vy som visar operativsystem, hårdvara
osv och hur olika burkar (noder i UML) kommunicerar med varandra
(protokoll osv). Deployment-vyn visar även vilka komponenter som
finns på vilken nod.
Dessutom kan det vid behov finnas ytterligare vyer:
- Processvyn visar processer och trådar. Vad de
ansvarar för, hur de samarbetar osv.
- Datavyn visar persistent data (till exempel i en
relationsdatabas) och hur det mappas till objekt.
- Use case-vyn visar use case som genom sin funktion eller
sina ickefunktionella krav har stor påverkan på
arkitekturen.
- Implementationsvyn visar uppdelningen av den exekverbara
koden (jar-filer, dll:er, html-sidor osv).
Varning för vattenfallsprocesser!
Det kan låta som om den här redogörelsen
förespråkar någon sorts vattenfallsprocess, först
listas kraven på
arkitekturen, sedan tar vi fram en arkitektur som löser dem och
därefter
gör vi en design inom den framtagna arkitekturen. Så är
det absolut inte. Arbetet måste tvärtom vara iterativt.
Först
tar vi fram ett grovt utkast till kravspec och sedan implementerar vi
någon funktionalitet som tvingar oss att fundera över
arkitekturen. Den implementationen ska gå hela vägen till
kod av produktionskvalité. I varje följande iteration
förfinar vi kravspecen lite, genomför
eventuella förändringar i den befintliga arkitekturen (och i
koden)
och utvecklar ny funktionalitet som tvingar oss att fundera vidare
på
arkitekturen. En viktig milstolpe oavsett process är när vi
utvcklat
så mycket kod att arkitekturen är klar.
Hur utforma en arkitektur?
Riktlinjer och metoder för att ta fram en arkitektur ligger
utanför den här kursen. För att åstadkomma en bra
arkitektur krävs god kännedom om aktuella teknologier och
gärna även om alternativa teknologier. Vi ska bara ta en kort
titt på några viktiga principer.
- sevice-based capabilities
Capabilities är observerbara egenskaper hos systemet, till exempel
säkerhet och prestanda. Service-based betyder att systemet delas
upp i tjänster (services). En tjänst
tillhandahåller en viss funktionalitet till alla delar i
systemet. Tjänster kan ha med
systemets funktionalitet att göra, tex skatteberäknarna i
NextGen POS men kan också tillgodose de ickefunktionella kraven,
tex loggningstjänster, autenicieringstjänster,
lastbalansering, namntjänster osv.
Genom att dela upp systemet i tjänster åstadkoms flera
fördelar. De olika delarna blir lösare kopplade till
varandra, vi slipper duplicerad kod och det blir lättare att
återanvända komponenter i
andra applikationer. Vi kan också utan större problem flytta
runt tjänsterna mellan olika burkar (noder) och dela dem med andra
system.
- design goals
Detta är icke observerbara egenskaper hos systemet.
Exempel är att det ska vara modulärt (ha väl
avgränsade komponenter som inte är beroende av varandras
implementationer), proteced variations (se sidan Fler GRASP-mönster), low
coupling och high cohesion
(se Introduktion till
objektorienterad design), pluggable (det går anpassa
funktionalitet hos tjänster vid exekvering genom att skicka dem
objekt och implementationer), tydliga roller och ansvar för
olika komponenter.
Denna typ av mål nås genom ett väl övervägt
användande av till exempel ramverk, uppdelning i komponenter och
lager samt utformande av tydliga kontrakt och bra abstraktioner.
Resultatet av arbetet med dessa blir den logiska vyn av arkitekturen
(se ovan).
Många av dessa begrepp har vi redan stött på i samband
med design men här handlar det inte om egenskaper hos klasser och
objekt utan hos större komponenter och subsystem.
Arkitekturella mönster
Nu ska vi titta lite närmare på två arkitekturella
mönster som är mycket bra hjälpmedel för att
uppnå de egenskaper som presenterades under punkten design
goals ovan. De är Lager och MVC och behandlas
i kapitel 30 i Larman. Dessa är (eftersom de har
förtjänat benämningen mönster) plattformsoberoende.
Lager
Problem
- Hög koppling, förändringar i källkoden
på ett ställe tvingar fram förändringar på
ett otal antal andra ställen.
- Affärslogik är blandad med kod för
användargränssnittet.
- Tjänster (services) som tex persistens är blandad med
affärslogiken.
- Eftersom det är hög koppling mellan olika delsystem
är det svårt att dela upp arbetet mellan utvecklarna.
- På grund av den höga kopplingen är det
också svårt att underhålla systemet.
Lösning
- Dela upp systemet i olika lager. Ett lager utgör en
större del av systemet och består typiskt av flera paket
eller subsystem.
- Varje lager ska ha hög sammanhållning, utföra en
väl definierad uppgift. "Lägre" lager (längre från
användaren) ska vara mer generella och "högre" lager mer
applikationsspecifika.
- Det ska bara finnas kopplingar från högre till
lägre lager, inte tvärtom. Detta eftersom de högre
lagren är instabilare och de lägre lagren inte behöver
de högre för att utföra sin uppgift.
Det finns många olika mallar för hur ett system kan delas
upp i lager. Figur 30.1 på sid 451 i Larman är ett
förslag.
Exempel
Figur 30.2 på sid 452 visar hur NextGen POS kan delas upp enligt
förslaget i figur 30.1. Notera att detta är en arkitekturell
vy som alltså inte visar alla klasser och komponenter utan bara
de som behövs för att ge en förståelse för
strukturen. Som påpekats ovan är utvecklingen av
arkitekturen iterativ. Figur 30.2 är en skiss i en relativ tidig
iteration, Larman misstänker till exempel att det kommer till ett application
layer i en senare iteration.
Det är viktigt att göra klart för sig vilken koppling
det finns mellan olika paket och lager, detta visas i figur 30.3
på sid 454 i Larman. Notera att det både går att visa
mellan exakt vilka typer ett beroende finns (tex mellan Register
och ServicesFactory) och bara att det finns ett beroende
mellan paket (tex Domain till DBFacade). Det senare
kan användas om det inte är intressant mellan vilka typer
beroendet finns eller om många typer i ett paket är beroende
(så är fallet med beroendet från Domain till
DBFacade).
Det är lämpligt att rita interaktionsdiagram för att
illustrera beteendet i den den logiska vyn av arkitekturen. Dessa ska
då visa arkitekturellt viktiga scenarion, alltså
sådana som illustrerar samarbete mellan olika lager och paket.
Ett exempel finns i figur 30.5 på sid 456 i Larman. Notera hur
sambandet mellan paket och typer illustreras i UML, <PaketNamn>::<TypNamn>.
Notera också hur stereotyper (<<singleton>> och
<<subsystem>>) används för att förtydliga
diagrammet.
Samarbeten
Samarbeten mellan olika lager kan implementeras med hjälp av
designmönstren Facade, Controller och Observer.
Facade används lämpligtvis för att kapsla in subsystem
och därigenom åstadkomma Proteced Variations. Ett exempel
på det finns i figur 30.6 på sid 458 i Larman. Detta
gäller vid kommunikation från högre till lägre
lager eller mellan olika paket/subsystem inom samma lager.
Controller används som Facade vid anrop från Presentation
till Domain. Om det är få systemanrop används
lämpligtvis en facade controller (se sidan
med mönstret Controller) varvid lagret Application
utelämnas, se figur 30.7 på sid 459 i Larman. När
systemet växer och allt fler systemoperationer implementeras
kommer vi till slut till en punkt där facade controllern blir
otympligt stor. Då är det dags att dela upp den i use case
controllers och placera dessa i lagret Application som
då införs, se figur 30.8 och 30.9 på sid 460 i Larman.
Notera att varje systemoperation motsvaras av ett anrop från Presentation
till Domain (eventuellt via Application).
Controller används endast vid kommunikation från Presentation
till lägre lager.
Ovan hävdades att det inte skulle förekomma några
beroenden från lägre till högre lager. Det är
tyvärr nödvändigt att göra ett undantag från
den regeln. Det beror på att en systemoperation kan medföra
att stora delar av domänen (lagret domain) byter
tillstånd. Om någon av de typer som ändrar
tillstånd finns representerade på skärmen
(alltså i
Presentation) måste skärmbilden uppdateras så
att
den visar rätt tillstånd (det uppdaterade). Detta gör
att
Domain blir beroende av Presentation. Det här
problemet
är mycket välkänt och det finns många olika
lösningar
på det även om ingen av dem helt eliminerar beroendet. En
bra
och vanlig lösning som gör kopplingen mycket lös är
att
använda mönstret Observer. De objekt i Presentation
som
är intresserade av tillståndförändringar i Domain
impementerar då interfacet Observer (se sidan med mönstret Observer). Det
betyder att det i Domain bara finns beroenden av det
interfacet, inte av klasser som symboliserar fönster på
skärmen (vilket vore vansinne).
Detta är ett praktexempel på hur tjusigt det är att
använda
interface för att skapa en typ för en egenskap som beskrivs i
avsnittet om Observer och i avsnittet Använd interface
för egenskaper
skilda från en klass egentliga betydelse på sidan Några tankar om interface.
Diskussion
- Figur 30.12 på sid 464 i Larman visar hur databasen kan
ritas i den logiska vyn utan att blanda in konkreta databashanterare,
vilket hör till deployment-vyn.
- Det finns inte alltid något självklart och korrekt
svar på i vilket lager en viss typ hör hemma. Det är
heller inte meningsfullt att ägna onödig tid åt att
grubbla kring detta. Det viktiga är att det, förutom
undantaget ovan, inte finns beroenden nerifrån och upp.
Fördelar
- Högre sammanhållning och lägre koppling
- Lättare att återanvända funktionalitet på
olika ställen i samma system och även mellan olika system.
- Lättare dela upp ansvarsområden mellan utvecklarna.
- Lättare distribuera systemet på olika noder.
- Lättare byta ut, utöka och ändra i subsystem
Nackdelar
- Uppdelningen i lager kan medföra prestandaproblem. Det finns
dock ingen större anledning att oroa sig över detta eftersom
det är antalet nätverksanrop och inte antalet metodanrop som
påverkar prestandan. Det kritiska är alltså hur lagren
distribueras över olika noder, inte själva uppdelningen i
lager.
- Lager är ett oerhört användbart mönster som
tillämpas i närapå varenda applikation. Det är
dock
viktigt att komma ihåg att det inte alltid är rätt. Som
exempel är lager inte ett lämpligt mönster för
system
som ägnar sig åt databearbetning (signalbehandling) i flera
steg,
till exempel bildrendering.
Besläktade mönster
- Indirection (GRASP)
- Proteced Variations (GRASP)
- Low Coupling och High Cohesion (GRASP)
MVC (Model Viev Controller)
Problem
Hanteringen i koden av användargränssnittet får inte
vara blandad med affärslogiken eftersom det ger extremt
dålig sammanhållning och hög koppling.
Lösning
Dela upp systemet i de tre olika delarna model, view och controller.
Dessa svara mot lagren Domain, Presentation och Application som
definieras i mönstret lager ovan. MVC är egentligen "bara"
principer för hur dessa tre lager ska kommunicera med varandra.
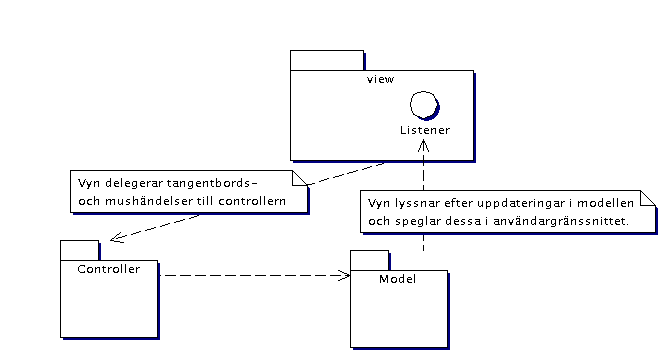
- Kommunikation mellan vyn och controllern
Vyn tar emot inmatningar från användaren, till
exempel i form av mus- och tangentbordshändelser. Dessa
översätts till applikationsspecifika händelser och
skickas till controllern. En systemoperation blir ett metodanrop
från vyn till controllern. Vyn innehåller
alltså ingen som helst logik eller flödeskontroll inom en
systemoperation och controllern innehåller ingenting som
relaterar till en viss typ av användargränssnitt (som HTML,
Swing eller MFC).
En intressant fråga är vem som är ansvarig för
flödeskontrollen mellan olika fönster. Antag till exempel att
vyn vid ett tillfälle visar en lista med lite information om olika
element. Om användren
klickar på ett element ska det visas detaljerad information om
just
det elementet. Vem talar om att just fönstret med den detaljerade
vyn
ska visas efter fönstret med listan? I ett litet program kan detta
säkert utan större problem finnas i vyn. Det är dock
viktigt
att vara medveten om att det då finns logik i vyn som måste
kopieras
om vi byter UI. Blir programmet större är det nog
lämpligt
att bryta ut denna flödeskontroll till ett objekt som inte
hör
till ett visst användargränssnitt. Detta objekt har då
till
uppgift att utifrån aktuell vy och systemhändelse tala om
hur
nästa vy ser ut. Det blir väldigt flexibelt och
användbart om denna koppling läses från en fil.
Det är helt OK att vyn är beroende av controllern,
däremot ska controllern helst aldrig anropa vyn.
- Kommunikation mellan controllern och modellen
Controllern utgörs av facader till vyn. En systemoperation
som motsvaras av ett metodanrop till controllern resulterar ofta i fler
metodanrop från controllern till vyn. Controllern
innehåller
alltså flödeskontrollen inom en systemoperationerna,
däremot
innehåller den ingen logik.
Det är helt OK att controllern är beroende av
modellen, däremot får modellen aldrig någonsin anropa
controllern.
- Kommunikation mellan modellen och vyn
Detta är den svaga punkten i MVC och åtskilliga
hyllmetrar har skrivits om hur detta kan fungera.
Helst skulle det inte finnas någon kommunikation alls mellan
dessa två delsystem. Enda sättet att helt undvika det
är att all information från modellen till vyn skickas som
returparametrar till metodanropen från vyn via controllern till
modellen. Det fungerar tyvärr väldigt sällan eftersom
det blir för myckt data som ska gå den vägen. Dessutom
kan vyn uppdateras utan att användaren gjort något, till
exempel till följd av ett anrop från en annan process eller
av att någon timer löser ut.
Ett annat, ofta använt, alternativ är att vyn gör
metodanrop direkt till modellen och frågar efter dess
tillstånd. Att vyn då blir beroende av modellen är
förmodligen ingen stor katastrof. Värre är att vyn
lätt blir beroende av modellens implementation eftersom
modellen lämnar ut sitt interna tillstånd. Det kan vara
klurigt och lätt att glömma att på ett bra sätt
kapsla in modellen bakom facader och dessutom översätta allt
data som lämnas ut till någon sorts "modelloberoende"
format. Ett annat problem med denna lösning är att det
är en form av pollning. Vyn kan inte veta exakt när alla
delar av modellen byter tillstånd, den måste kolla med
jämna mellanrum för att se om så är fallet. Detta
kan resultera dels i onödigt många metodanrop från vyn
till modellen, dels i att det tar för lång tid innan
vyn uppdateras enligt modellens tillståndsförändringar.
En tredje lösning är den som föreslogs i mönstret
lager ovan, att objekt i vyn som är intresserade av modellens
tillstånd med hjälp av mönstret Observer lyssnar efter
modellen tillståndsförändringar. På det viset
slipper vi pollning, vyn anropas bara och bums när en
tillståndsförändring sker. Med denna lösning
slipper vi alla anrop från vyn till modellen, däremot blir
det anrop från modellen till vyn. Denna koppling är dock
väldigt låg eftersom det bara är till gränssnittet
Observer. Det finns fortfarande en risk att vyn blir
beroende av modellens implementation eftersom modellen fortfarande
måste skicka sitt data till vyn. Om allt data skickas
med vid anropen av Observer blir dock risken mindre eftersom
vi
slipper metodanrop från vyn till modellen.
Det finns ytterligare lösningar med dessa är de vanligaste.
Fördelar
- Högre sammanhållning och lägre koppling eftersom
logik och användargränssnitt inte blandas.
- De olika delsystemen kan utvecklas och underhållas separat.
- Det går att byta användargränssnitt eller att ha
flera användargränssnitt samtidigt utan att det
påverkar modellen.
- Logiken kan exekveras utan användargränssnitt, till
exempel kan den ta emot meddelanden eller exekvera någon sorts
batcher.
Besläktade mönster
- Lager (POSA)
- Low coupling och High cohesion (GRASP)
Sammanfattning
Vi har nu tittat relativt noga på arbetet med den logiska vyn av
arkitekturen, dvs hur vi kan nå eftersträvansvärda
design goals (se ovan), detta ingår också i
laborationskursen. Anledningen till att vi fokuserat på det
är att det i mångt och mycket är "designliknande" och
plattformsoberoende kunskaper. Däremot
har vi inte tagit upp något om deployment-vyn, dvs hur vi
väljer
och kombinerar operativsystem, applikationsservrar, hårdvara
eller
någon annan teknologi eftersom detta egentligen är ett helt
annat
område än vad den här kursen täcker.
Uppgift
- Fundera på indelning i lager för att
banksystem.
- Skissa på kod för de olika sätten att
implementera
kommunikationen mellan modellen och vyn i MVC. Upptäcker du
några
speciella klurigheter? Verkar det vara någon strategi som är
speciellt
lätt eller svår?